Chapter 6 Audio data
6.1 Sound
Tina Marie Diamantini does such a great job in introducing the basic idea of sound here The Physics of Sound: How We Produce Sounds, so much of the materials in this section were copied from there with very minor changes.
6.1.1 Production of sound
A sound originates in the vibration of an object, which makes the air or another substance such as water and metal around the object vibrate. The vibration of the air moves outward an audible wave of pressure. For example, the human voice is produced by vocal cords. When air from our lungs passes through the vocal cords, a vibration is produced. This vibration produces vocal sounds. The tighter the vocal cords, the more rapidly the vocal cords vibrate and the higher the sounds that are produced. This is what causes human voices to have different pitches.
6.1.2 Sound wave
A sound wave is a transfer of energy as it travels away from a vibrating source. Sound waves are formed when a vibrating object causes the surrounding medium such as air to vibrate. A sound’s volume, how loud or soft it is, depends on the sound wave. The more energy put into making a sound or a sound wave, the louder the volume will be. A sound wave enters the ear and is changed into nerve signals, which are interpreted by the brain.
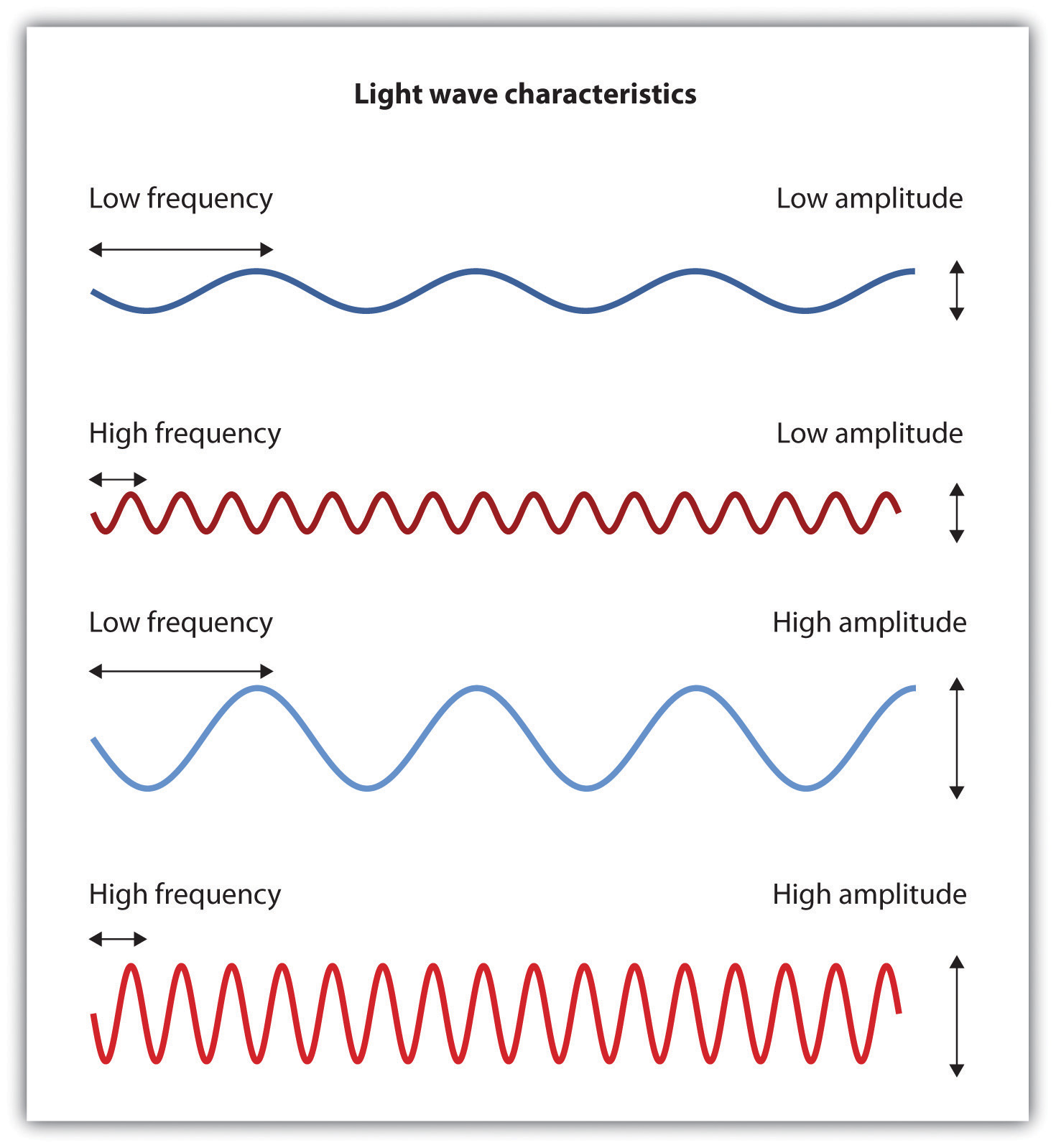
There are three aspects of a sound wave that cause different types of sounds to be produced, frequency, wavelength, and amplitude. Sound waves vibrate at different rates or frequencies as they move through the air. Frequency is measured in cycles per second, or Hertz (HZ) – 1 vibration a second is 1 Hertz.

A wavelength is the length of one cycle of sound and the inverse of the frequency. The period of a sound wave is the time taken for one wavelength to pass a certain point before a new wave begins to pass by. Longer wavelengths have a lower pitch. The lowest tones that your ears can hear are about 16 vibrations per second, or 16 Hz. Amplitude specifies the sound’s loudness. A low amplitude will produce a soft sound and a higher amplitude will produce a louder sound.
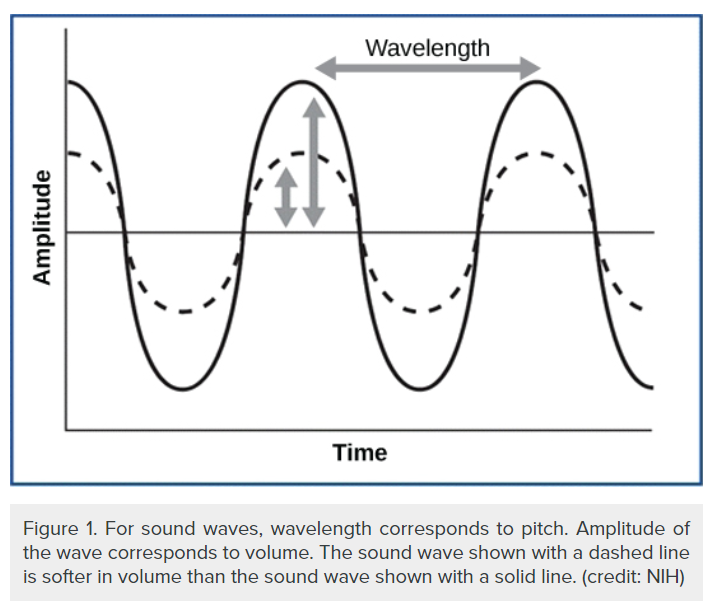
6.1.3 Difference between Pitch and Loudness
This two phenomena seem to be same sometimes but they are not exactly the same. They differ on the basis of their tone quality. The pitch of a sound is our ear’s response to the frequency of sound. Whereas loudness depends on the energy of the wave. In general, the pitch is the reason behind the difference in voice quality of different individuals.
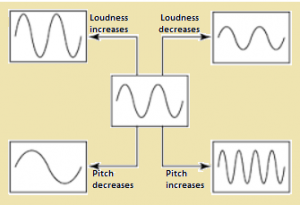
The pitch of a sound depends on the frequency while loudness of a sound depends on the amplitude of sound waves. Some musicians, who have been trained are capable of detecting a difference in frequency between two separate sounds that is as little as 2 Hz.
6.2 Digital audio data
Sound can be recorded in digital form. The process first determines the number of times per second, each time called a sample, to make the record and then record the amplitude of the sound at the time. The amplitude is recorded using binary numbers. If one binary number is used, it is called 1 bit. For typical audio, 16 bits are used. The 16 bits can be converted into an integer number range from 1 to 2^16=65,536 or a number between -32,768 to +32,767.
The number of times that the sound is recorded per second is calling a sampling rate. For recording music, the sampling rate of 44.1 kHz is often used. But 96 kHz or even 192 kHz is currently also used.
Depending on the purpose, a higher sampling rate might not be the best. For example, human voice has a frequency range of approximately 0.3 to 3 kHz. Therefore, for speech, 8 kHz would be good enough.
6.2.1 Audio format
Pulse-code modulation (PCM) is one digital wave format. For PCM, the amplitude of the analog signal is sampled regularly at uniform intervals and round to the nearest integer value.
Other formats are used in the digital recording, too, such as the IEEE float format. In this format, a float number is used to represent the amplitude.
6.2.2 File format
The WAV file is one of the simplest and oldest digital formats. It simply takes audio signals and converting them to binary data. WAV is an uncompressed format - this means the recording is reproduced without any loss in audio quality. It can also record the highest recording rates with tremendous dynamic ranges (up to 192 kHz).
MP3 is a compressed audio format. For example, one can compress a wav audio to mp3 format. In the process, the quality of the audio will be reduced. However, mp3 can take significantly less disk space.
6.3 Read data into R
6.3.1 Wave data
To read WAV data into R, we can use the function readWave of the package tuneR. The file splash.wav is from the collection of BBC sound effects.
splash <- readWave('data/splash.wav')
splash
##
## Wave Object
## Number of Samples: 1061340
## Duration (seconds): 24.07
## Samplingrate (Hertz): 44100
## Channels (Mono/Stereo): Stereo
## PCM (integer format): TRUE
## Bit (8/16/24/32/64): 166.3.2 Read MP3 files
The audio file 2300.mp3 is the recorded interview from a study. The function readMP3 can be used here.
p2300 <- readMP3('data/2300.mp3')
p2300
##
## Wave Object
## Number of Samples: 15495552
## Duration (seconds): 351.37
## Samplingrate (Hertz): 44100
## Channels (Mono/Stereo): Stereo
## PCM (integer format): TRUE
## Bit (8/16/24/32/64): 16
tuneR::play(p2300)For other formats of data, one can first convert them into wav or mp3 format.
6.4 Process audio data
6.4.1 WAV data
To read WAV data into R, we can use the function readWave of the package tuneR. The file splash.wav is from the collection of BBC sound effects.
splash <- readWave('data/splash.wav')
splash
##
## Wave Object
## Number of Samples: 1061340
## Duration (seconds): 24.07
## Samplingrate (Hertz): 44100
## Channels (Mono/Stereo): Stereo
## PCM (integer format): TRUE
## Bit (8/16/24/32/64): 16
listen(splash)- The data are saved as a Wave class in R. The component of the object includes the following.
- Number of samples, this is the traditional sample size
- Sample rate in Hz. Note that Number of samples / Sample rate = number of second or duration of the audio.
- Bit of the audio (8/16/24/32/64)
- The audio format, PCM or not (IEEE float)
- Whether the audio is mono or stereo. In monaural sound one single channel is used. It can be reproduced through several speakers, but all speakers are still reproducing the same copy of the signal. In stereophonic sound, more channels are used (typically two). Each speaker can reproduce one channel of signal. The package tuneR can only handle at most two channels.
str(splash)
## Formal class 'Wave' [package "tuneR"] with 6 slots
## ..@ left : int [1:1061340] 0 0 0 -1 0 -1 -1 -1 0 -1 ...
## ..@ right : int [1:1061340] 0 0 0 -1 0 -1 -1 0 -1 0 ...
## ..@ stereo : logi TRUE
## ..@ samp.rate: int 44100
## ..@ bit : int 16
## ..@ pcm : logi TRUENote that the actual data, the amplitude of each sample is in the left and right components, or slots, of the wave class. We can take out the data and get some basic information.
left.channel <- splash@left
right.channel <- splash@right
length(left.channel)
## [1] 1061340
length(left.channel)/splash@samp.rate
## [1] 24.06667
summary(left.channel)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -32023.00 -71.00 -3.00 -23.08 11.00 26955.00We can play the audio in R. But it actually opens an external audio player.
tuneR::play(splash)The audio can be plotted in waves. This is often called an oscillogram.
plot(splash)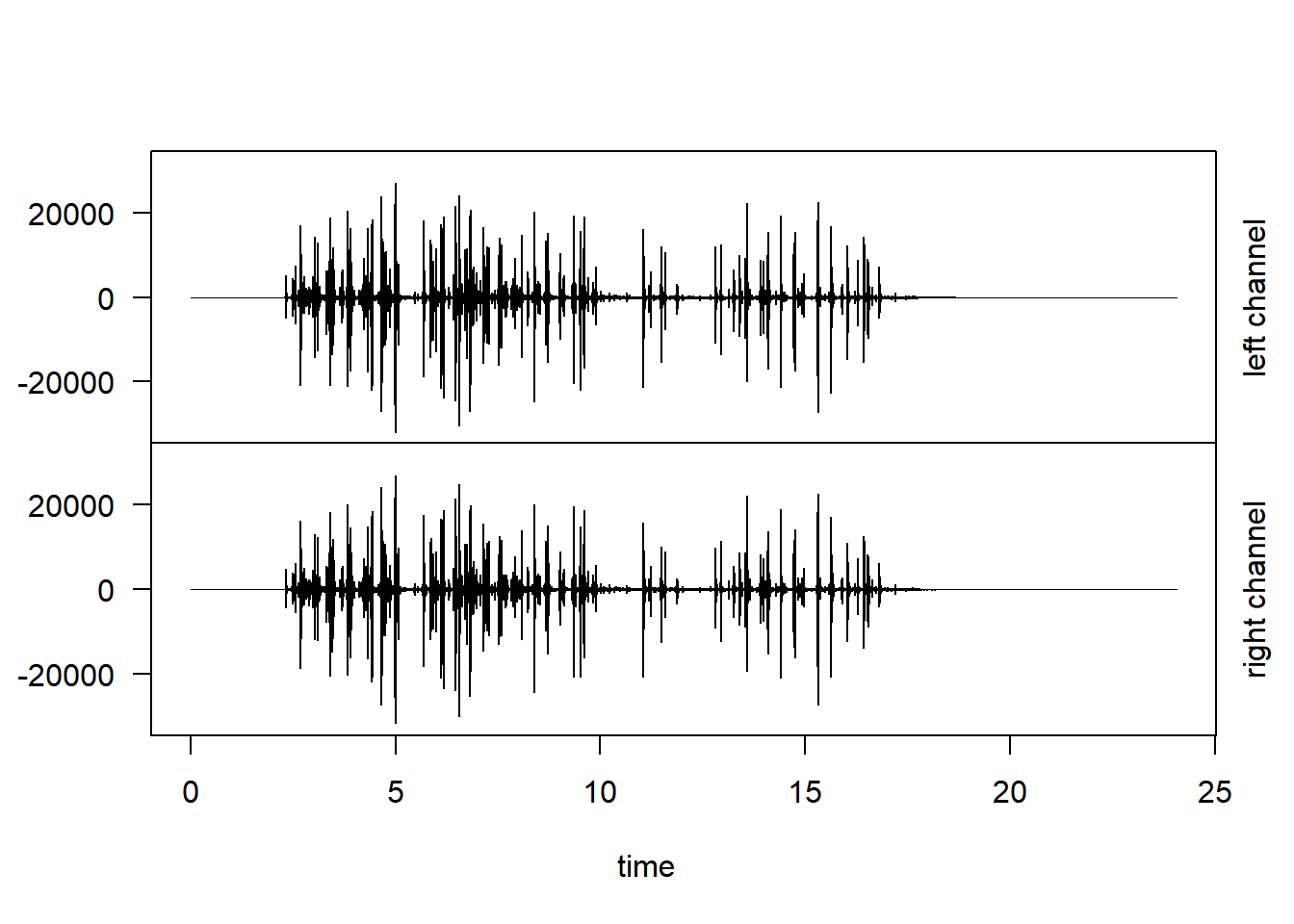
plot.ts(splash@left)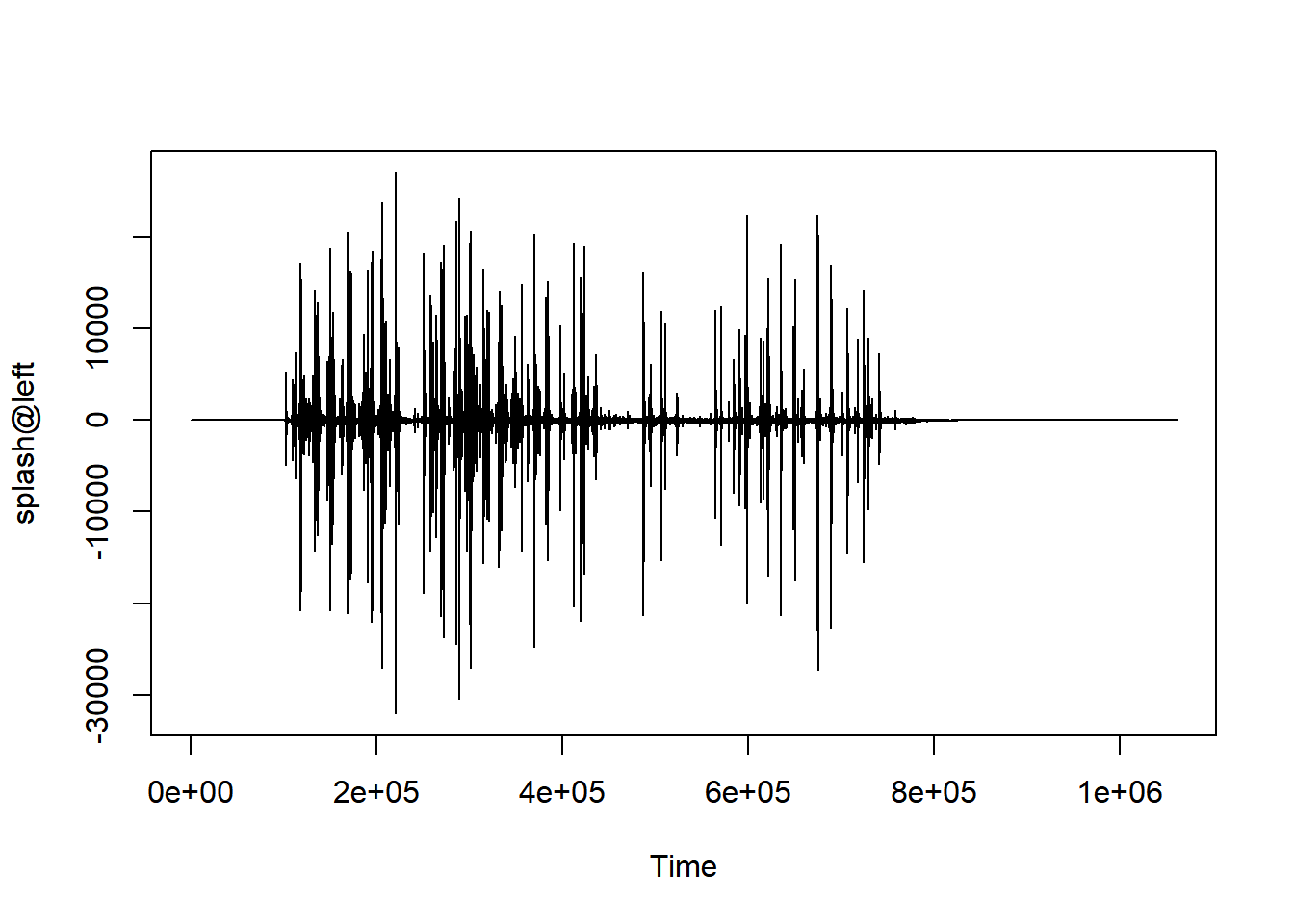
We can take a closer look at the data.
splash@left[1:100]
## [1] 0 0 0 -1 0 -1 -1 -1 0 -1 -1 -1 0 -1 0 -1 -1 -1 -1 -1 0 0 -1 -1 0
## [26] 0 -1 0 0 0 0 -1 -1 -1 -1 0 -1 -1 0 0 -1 -1 0 -1 -1 0 0 0 -1 0
## [51] 0 0 -1 0 -1 -1 -1 0 0 -1 0 0 0 0 -1 -1 -1 -1 0 0 0 -1 -1 -1 0
## [76] 0 -1 0 -1 0 -1 -1 0 -1 0 0 0 -1 0 -1 0 0 0 -1 0 -1 0 -1 0 0
splash@left[150010:150100]
## [1] -6105 -3965 -388 3261 5633 5989 4057 420 -3074 -5304 -5554 -3339
## [13] 541 3665 3678 834 -2272 -4028 -4336 -2873 305 4184 7016 6954
## [25] 3680 -861 -4101 -4893 -3658 -978 1542 2764 2841 1881 -159 -3051
## [37] -4440 -3142 -432 2452 4811 5711 4027 993 -1723 -4043 -4916 -3351
## [49] -617 1335 2295 2689 1176 -2223 -4271 -3161 -500 1995 3990 4924
## [61] 4144 2060 -469 -2692 -3735 -2504 728 3047 2101 -1274 -4020 -4031
## [73] -3174 -3438 -3391 -1243 2313 5164 6826 7126 5343 2615 1475 2078
## [85] 2577 2292 433 -2872 -5873 -7626 -8364The amplitude of a wave can be characterized by (1) the instantaneous amplitude, (2) the maximum amplitude, (3) the peak-to-peak amplitude, or (4) the root-mean-square amplitude RMS.
rms(splash@left)
## [1] 1093.2416.4.1.1 Make sound
- Example 1 - single channel, random noise
sound1 <- Wave(left=sample(-32768:32767, size=44100*5, replace=TRUE))
tuneR::play(sound1)- Example 2 - two channels, random noise
sound2 <- Wave(left=sample(-32768:32767, size=44100*5, replace=TRUE),
right=sample(-3276:3276, size=44100*5, replace=TRUE))
tuneR::play(sound2)- Example 3 - a sinus sound
left <- seq(0, 2*pi, length = 44100*2)
left <- round(32000 * sin(440 * left))
sound3 <- Wave(left = left)
tuneR::play(sound3)- Example 4. Extract a part of the sound - from 2nd second to 18th second.
splash.part <- extractWave(splash, from=2, to=18, xunit='time')
tuneR::play(splash.part)- Example 5. Remove silence of low noise
The function noSilence() of tuneR cuts off silence that can occur at the start and/or end of a sound; in other words noSilence() is a trim function.
sound5 <- noSilence(splash, level=128)
plot(sound5)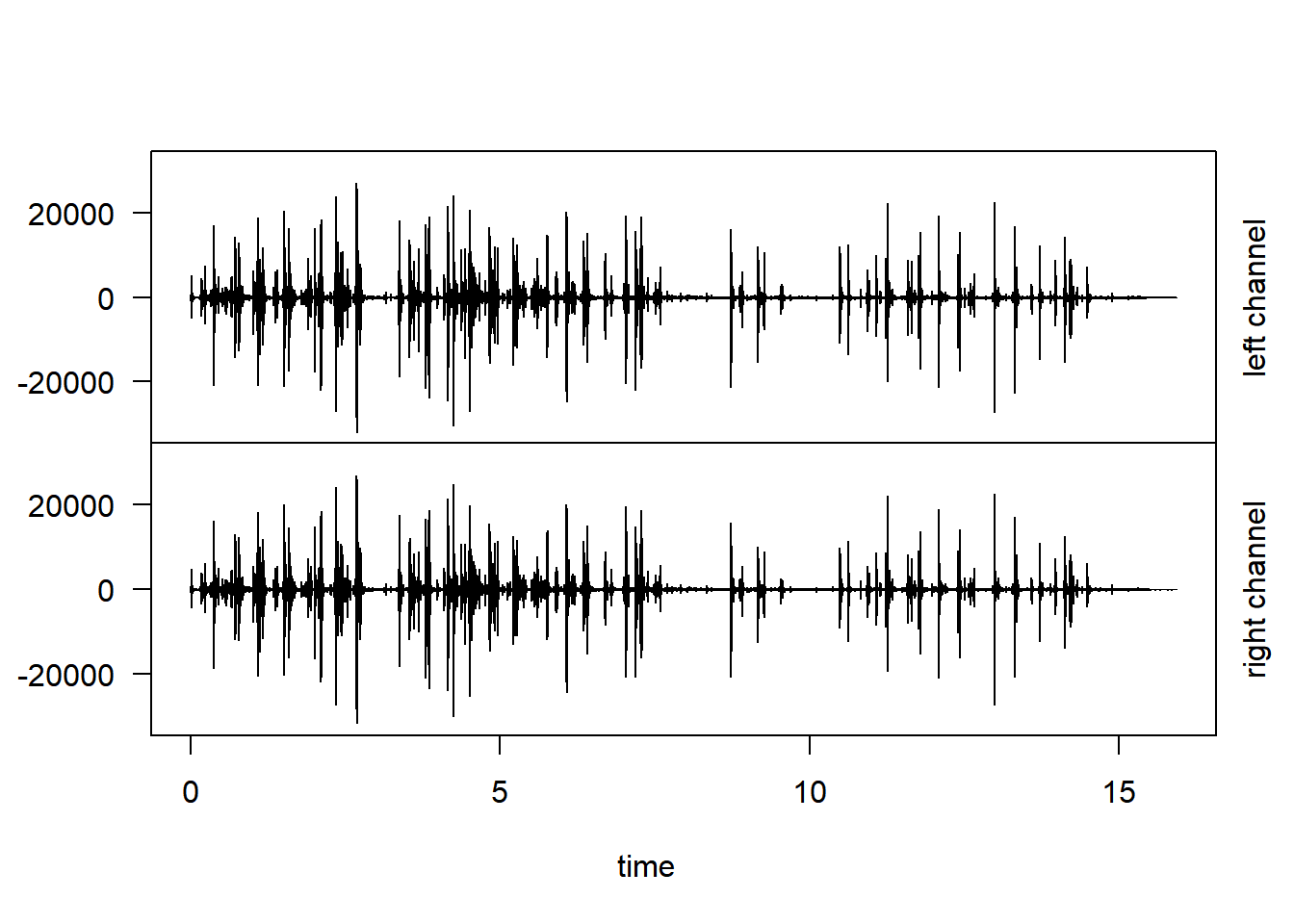
tuneR::play(sound5)The function zapsilw() of seewave removes every sample that are below a defined amplitude threshold anywhere, not only at the start or at the end of the sound.
sound6 <- zapsilw(splash, threshold = 1, output = "Wave")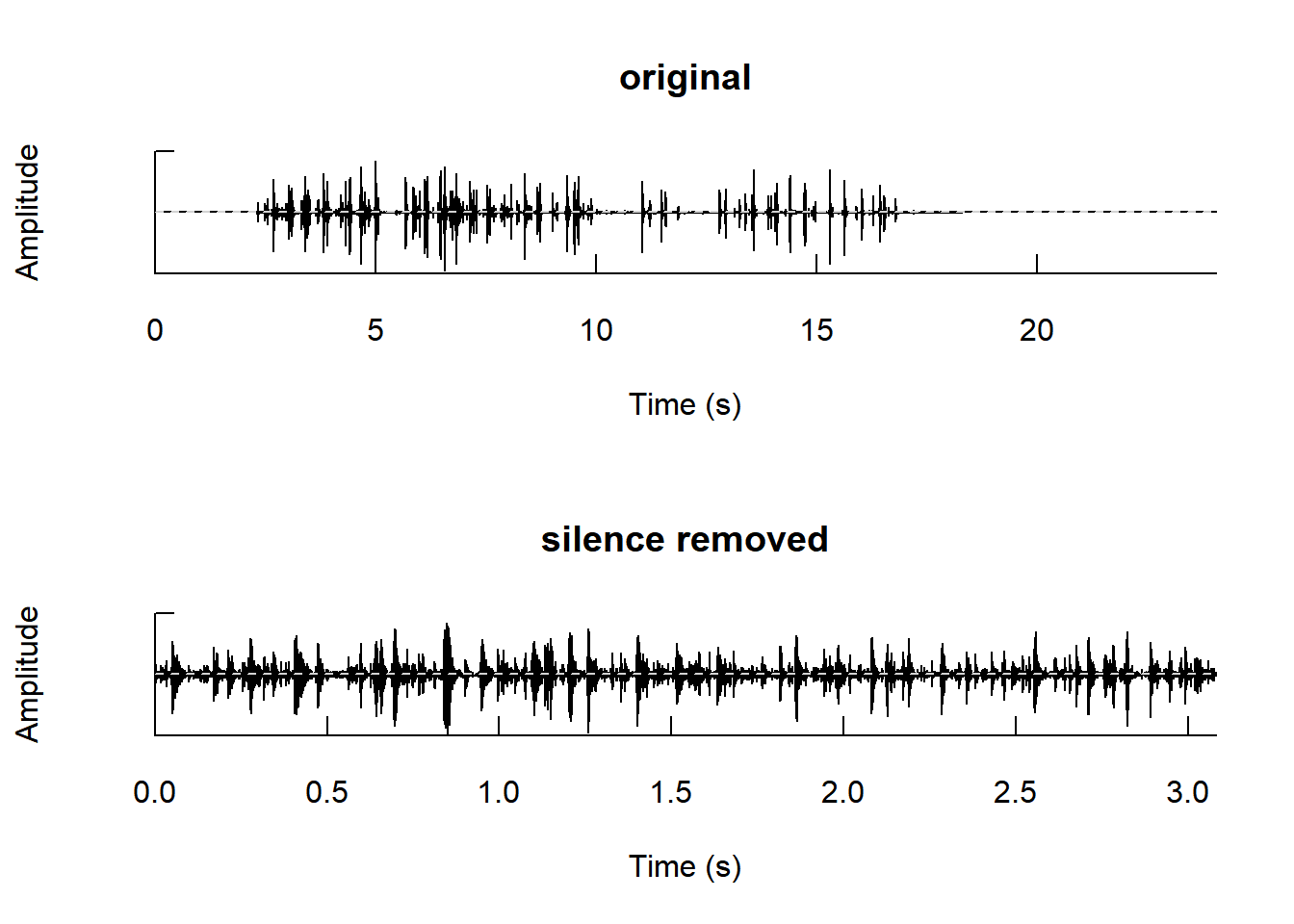
tuneR::play(sound6)- Example 6. Mix sound together
sine.wave <- sine(440, length(splash@left), bit=16, stereo=TRUE, pcm=TRUE)
splash.new <- splash + sine.wave
splash.new <- normalize(splash.new, "16")
tuneR::play(splash.new)- Example 7. Downsample
splash.down <- downsample(splash, 11025)
tuneR::play(splash.down)- Example 8. Play the audio slower or faster
If we play more data in a second, we play it faster; otherwise, slower. We can use the function listen from the package seewave to do this.
f <- splash@samp.rate
listen(splash, f)
listen(splash, f*.7)
listen(splash, f*1.5)- Example 9. Record a sound
The R package audio can be used to record sound directly within R.
s <- 1
f <- 44100
class.record <- s*f
record(class.record, rate=f, channels=2)
listen(class.record, f)- Example 9. Delete a part. The function
deletewfrom theseewavepackage can be used.
splash.del <- deletew(splash, from = 18, output="Wave")
plot(splash.del)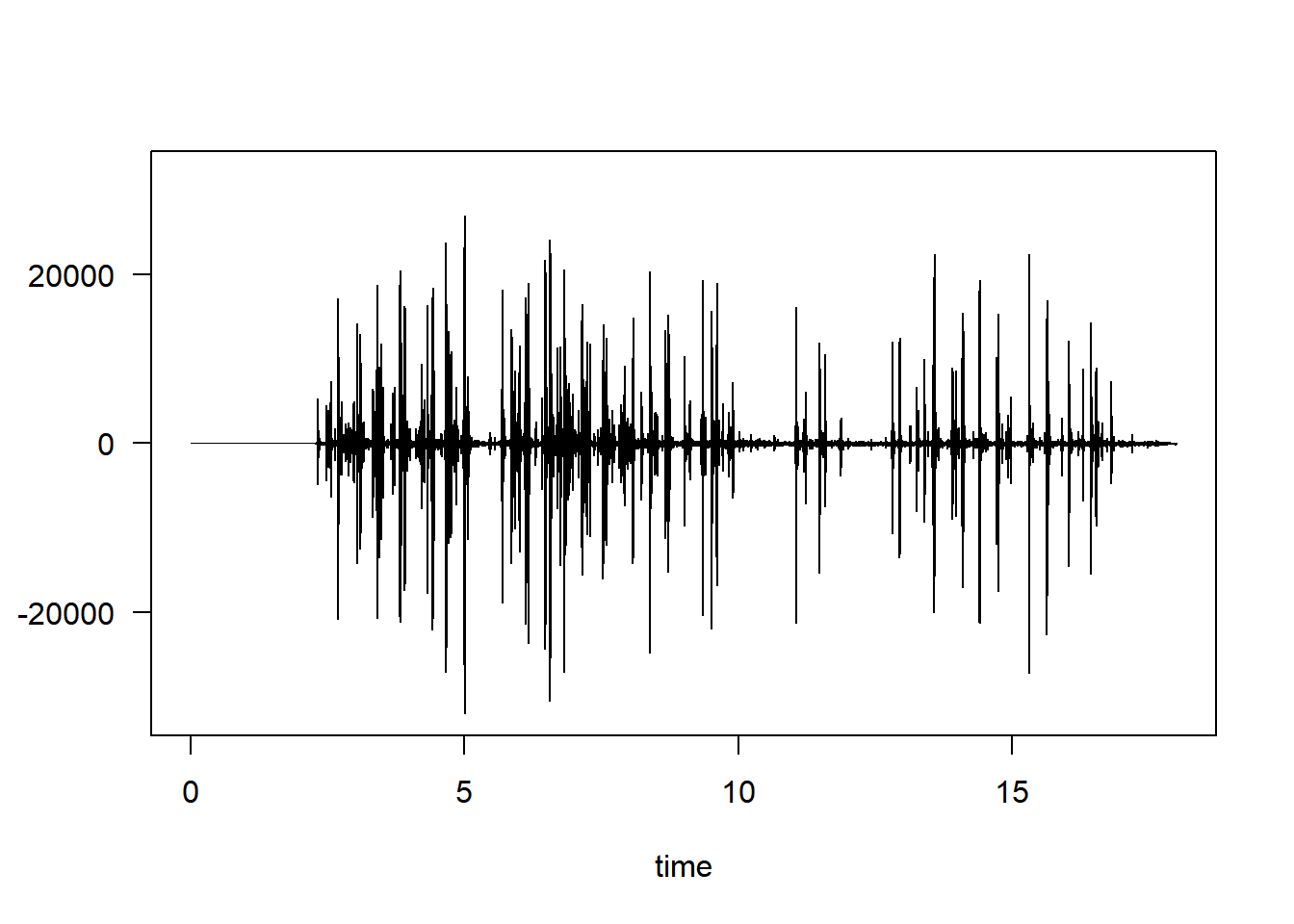
splash.del
##
## Wave Object
## Number of Samples: 793799
## Duration (seconds): 18
## Samplingrate (Hertz): 44100
## Channels (Mono/Stereo): Mono
## PCM (integer format): TRUE
## Bit (8/16/24/32/64): 16- Example 10. Connect audios together
splash.twice <- bind(splash.del, splash.del)
plot(splash.twice)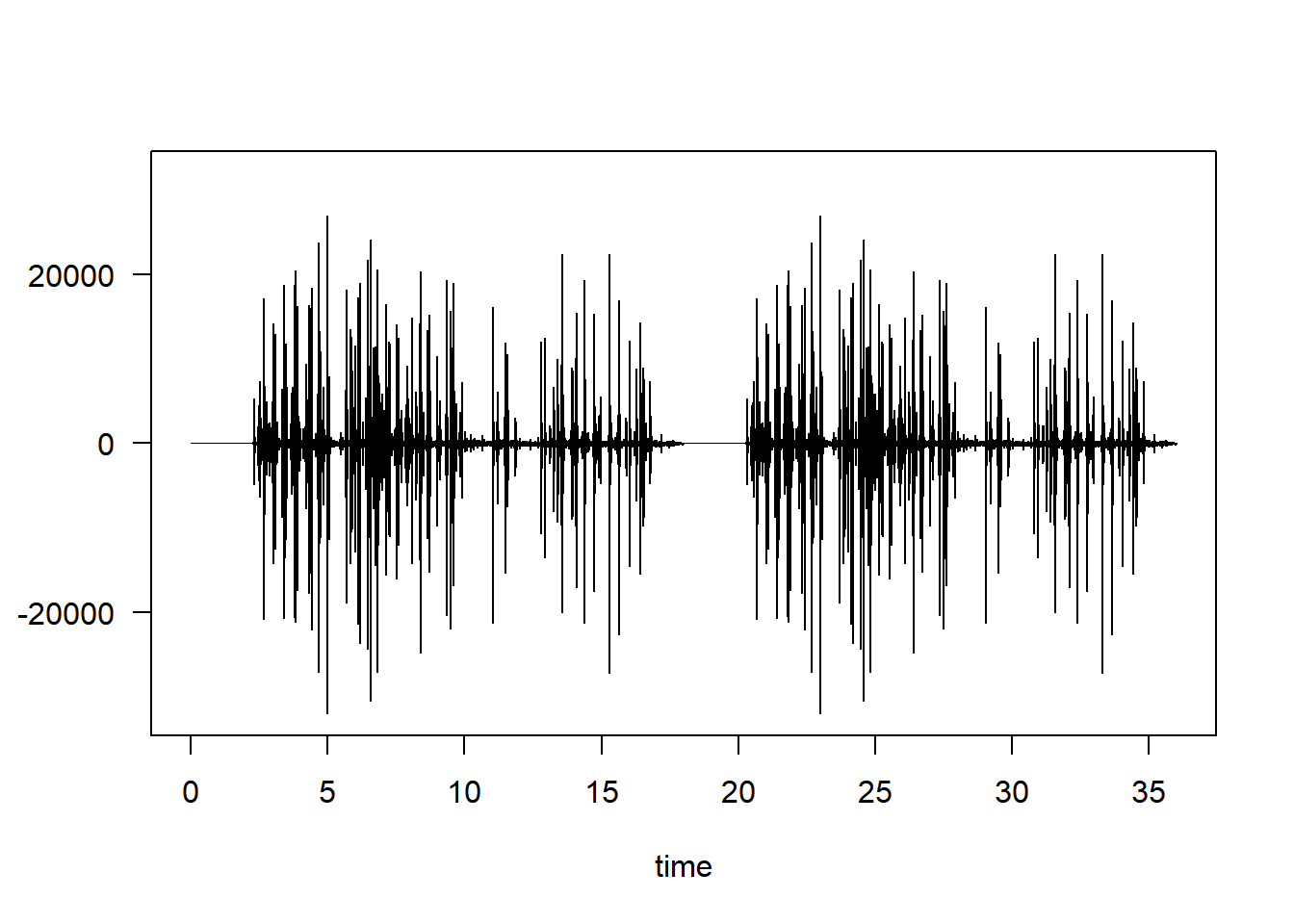
splash.twice
##
## Wave Object
## Number of Samples: 1587598
## Duration (seconds): 36
## Samplingrate (Hertz): 44100
## Channels (Mono/Stereo): Mono
## PCM (integer format): TRUE
## Bit (8/16/24/32/64): 16For the save audio, we can repeat them directly.
splash.rep <- repw(splash.del, times=2, output="Wave")
splash.rep
##
## Wave Object
## Number of Samples: 1587598
## Duration (seconds): 36
## Samplingrate (Hertz): 44100
## Channels (Mono/Stereo): Mono
## PCM (integer format): TRUE
## Bit (8/16/24/32/64): 16The function mutew can replace some sound with silence and the function addsilw can insert silence at the start, middle, or end of a sound.
- Save audio to file
writeWave(splash.down, "data/splash.down.wav")The function savewave from the package seewave has more control over the saving of the file.
## change the speed
savewav(splash, f = f*0.7, filename = 'data/splash.slow.wav')
## change the volumne of the audio
savewav(splash, f = f,
filename = 'data/splash.test.wav',
rescale = c(-1000, 1000))The function save.wave from the audio package can also be used to save wave data. Unlike tuenR and seewave, the package audio expresses the data in values between -1 and 1. It only allows 8 bits or 16 bits format. In order to conform to the format, we can use the function audioSample to construct audios. For mono audio, a vector can be used and for stereo audio, a matirx can be used.
The following construct the audio using the splash data.
splash.matrix <- rbind(splash@left, splash@right)
splash.audio <- audioSample(splash.matrix, rate=44100, bits=16)
str(splash.audio)
## 'audioSample' num [1:2, 1:1061340] 0 0 0 0 0 ...
## - attr(*, "rate")= num 44100
## - attr(*, "bits")= int 16
save.wave(splash.audio, 'data/splash.audio.wav')6.4.1.2 Practice
Each note has a frequency.

The notes can be easily expressed as data. Therefore, one can compose music based on these note frequencies. Using the notes below, try to compose it in R.
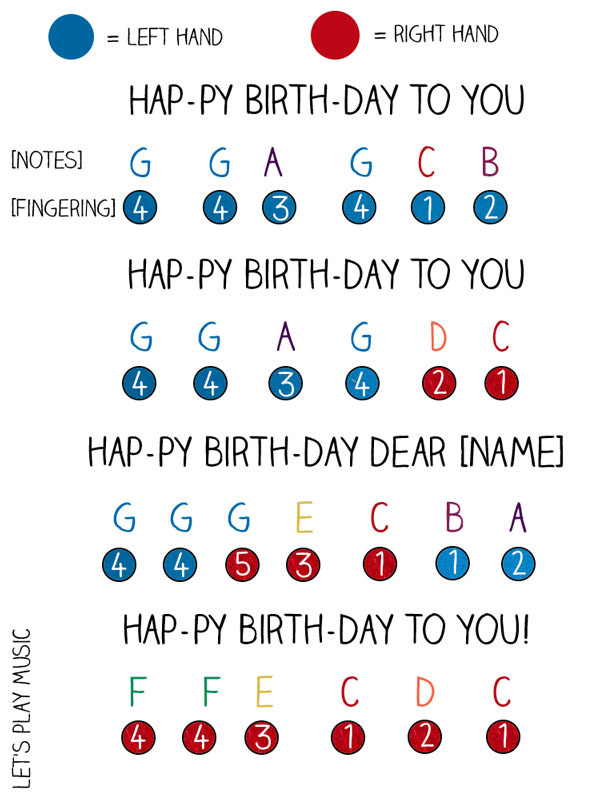

## digital music
time <- 0.3
hb <- bind(
sine(392, time/2, xunit='time'), #G
sine(392, time/2, xunit='time'), # G
sine(440, time, xunit='time'), # A
sine(392, time, xunit='time'),
sine(262, time, xunit='time'),
sine(494, time, xunit='time')
)
listen(hb)6.4.2 Frequency analysis
In addition to amplitude and time, there is the third dimension of sound: frequency. Understanding the frequency of a sound is actually not easy at all. The Fourier transformation or Fourier analysis is a popular method in frequency analysis. The basic idea is that a complex waveform can be expressed into an infinite sum of simple waveforms each with its own frequency, amplitude, and phase. It expresses a soundwave into an infinite series of sine and cosine functions.
The function periodogram() of tuneR converts a waveform to frequency.
splash.p <- periodogram(mono(splash, 'left'))
plot(splash.p)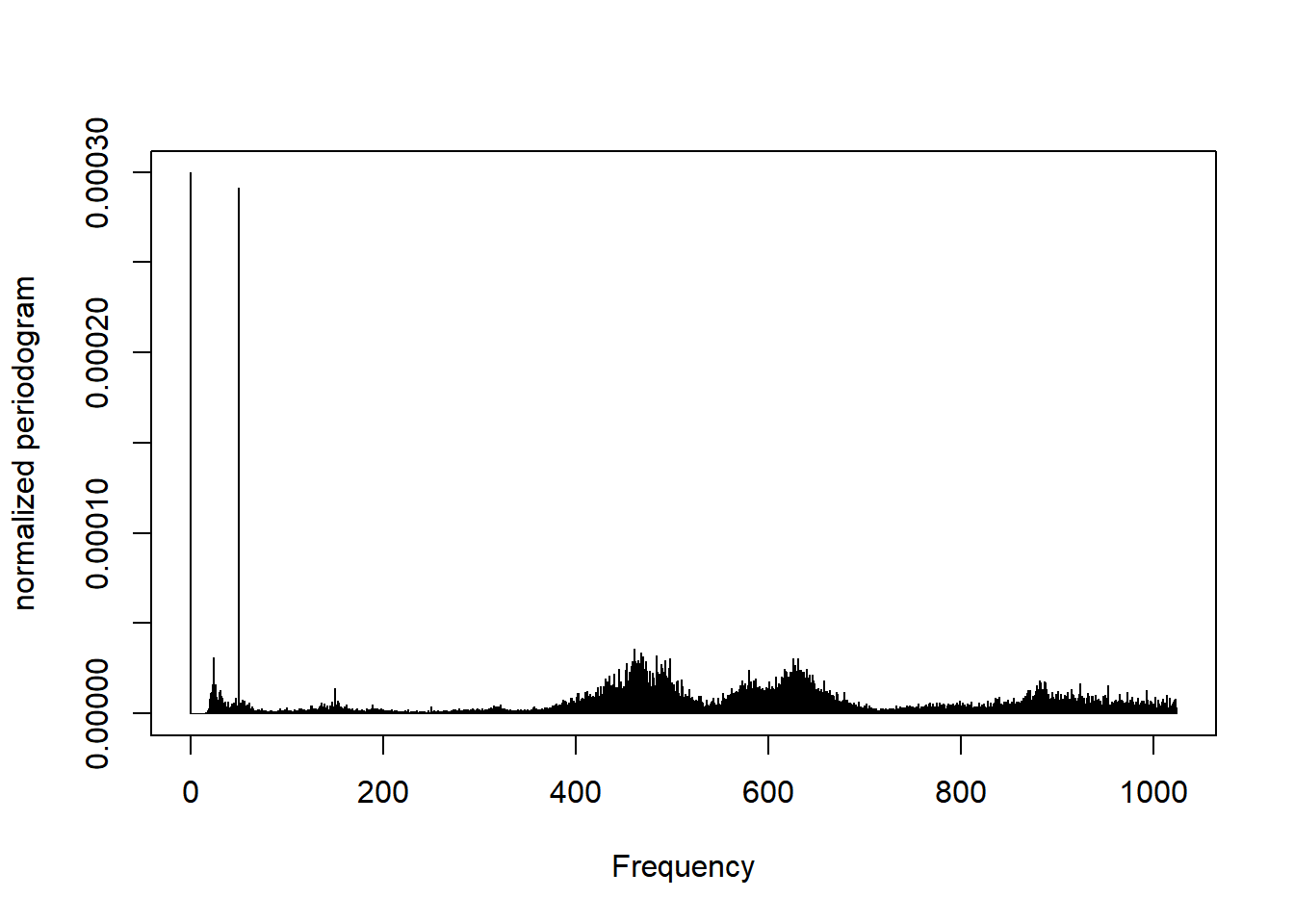
splash.p <- spec(splash, type='h') 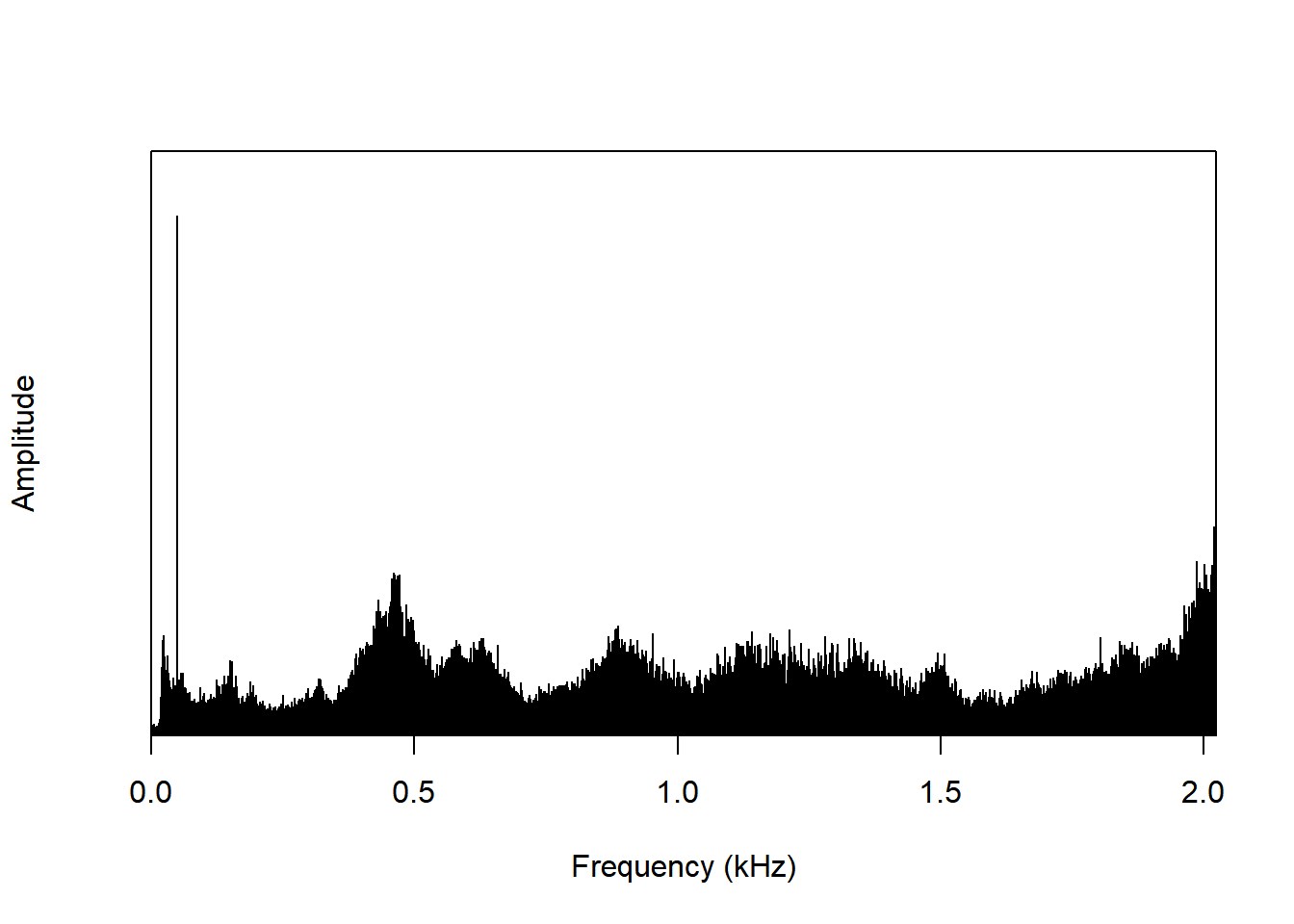
head(splash.p)
## x y
## [1,] 0.000000e+00 1.00000000
## [2,] 4.155125e-05 0.58382365
## [3,] 8.310249e-05 0.01871654
## [4,] 1.246537e-04 0.12809576
## [5,] 1.662050e-04 0.04448145
## [6,] 2.077562e-04 0.01645753As an example, let’s generate some data with known frequencies - 220, 440, 1440.
ex.wave <- sine(440, duration = 2*44100) +
sine(220, duration = 2*44100) +
sine(1440, duration = 2*44100)
listen(ex.wave)
ex.wave.freq <- periodogram(ex.wave)
plot(ex.wave.freq, xlim=c(0, 1500))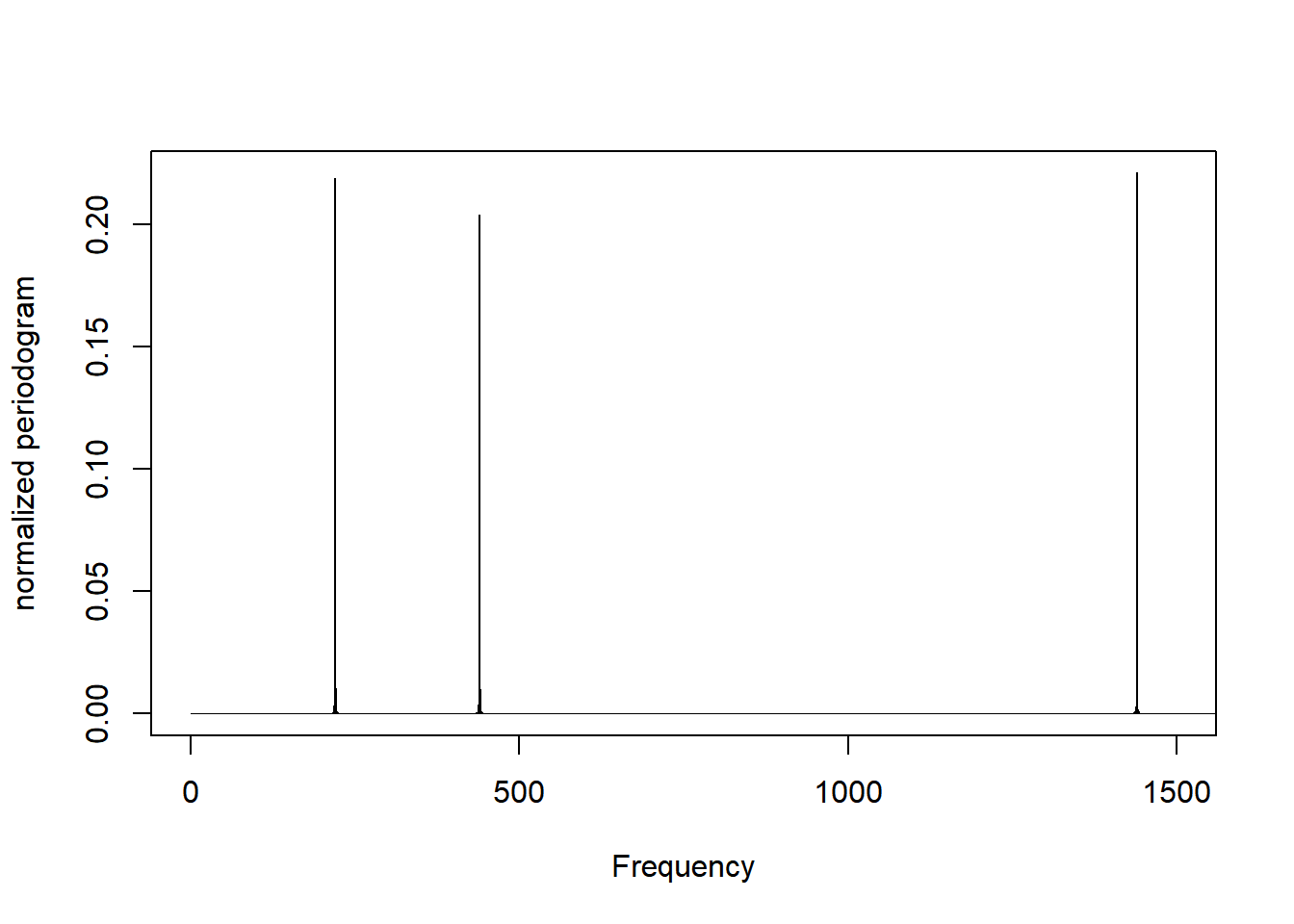
We can identify the peaks of the frequency.
ex.p <- spec(ex.wave, plot=FALSE)
ex.peaks <- fpeaks(ex.p, nmax=3)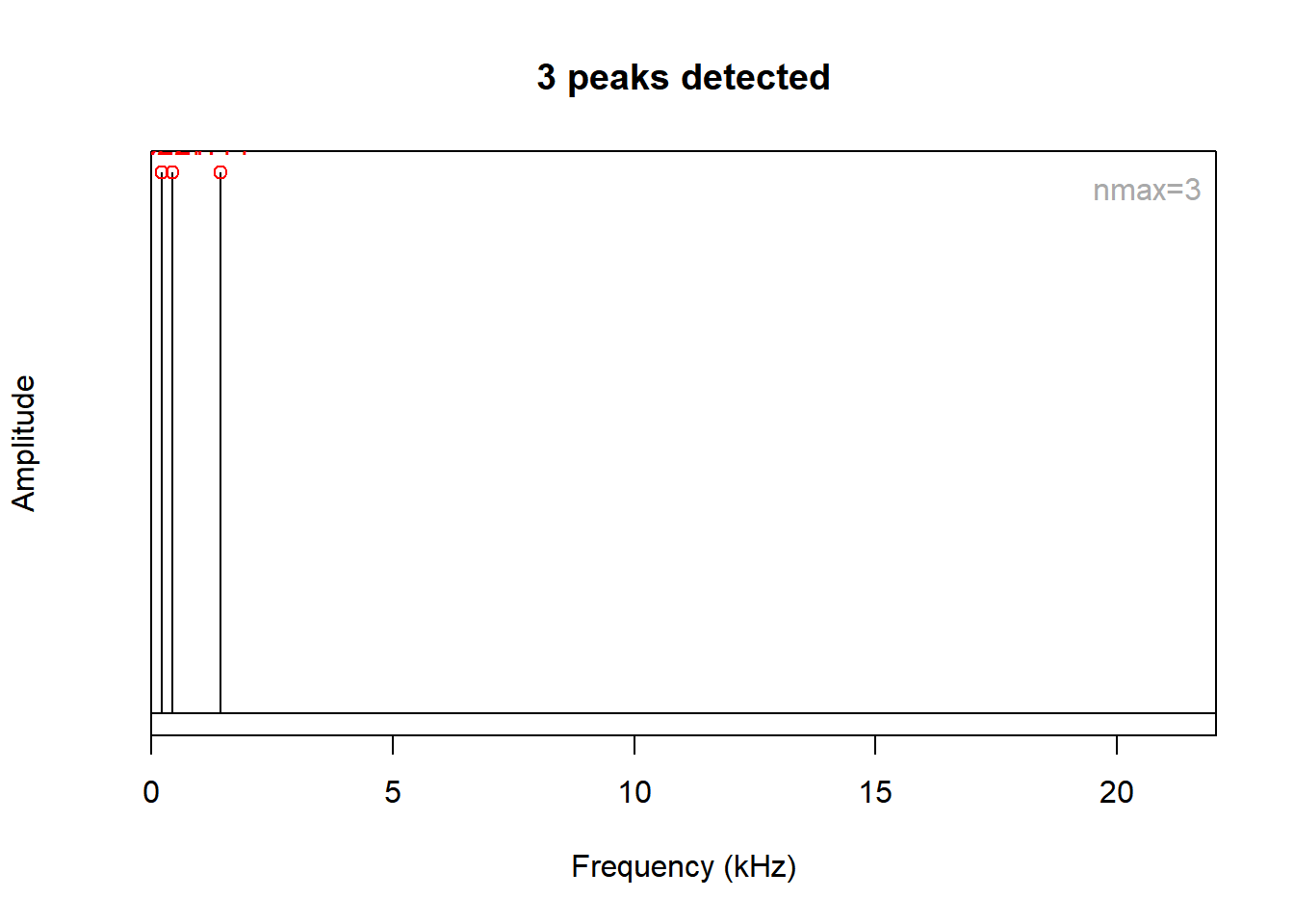
#ex.peaks6.4.3 Frequency filters
Audio recordings are far from perfect and, therefore, it is often necessary to clean up the recordings by removing a part of the frequency spectrum. For example, the voiced speech of a typical adult male will have a fundamental frequency from 85 to 180 Hz, and that of a typical adult female from 165 to 255 Hz.
We can use low-pass filter, high-pass filter and band-filter.
- low-pass filter allows the passage of frequencies lower than a cutoff frequency and attenuating the frequencies higher than that.
- high-pass filter allows the passage of frequencies higher than a cutoff frequency and attenuating the frequencies lower than that.
- band-pass filter allows the passage of frequencies between a lower cutoff frequency and a upper cutoff frequency.
An example of the hig-pass filter is the preemphasis filter that is often used in speech analysis to remove noise.
question1.2 <- extractWave(p2300, 21, 33, xunit="time")
question1.2
##
## Wave Object
## Number of Samples: 529201
## Duration (seconds): 12
## Samplingrate (Hertz): 44100
## Channels (Mono/Stereo): Stereo
## PCM (integer format): TRUE
## Bit (8/16/24/32/64): 16
listen(question1.2)
p2300.p <- spec(question1.2) 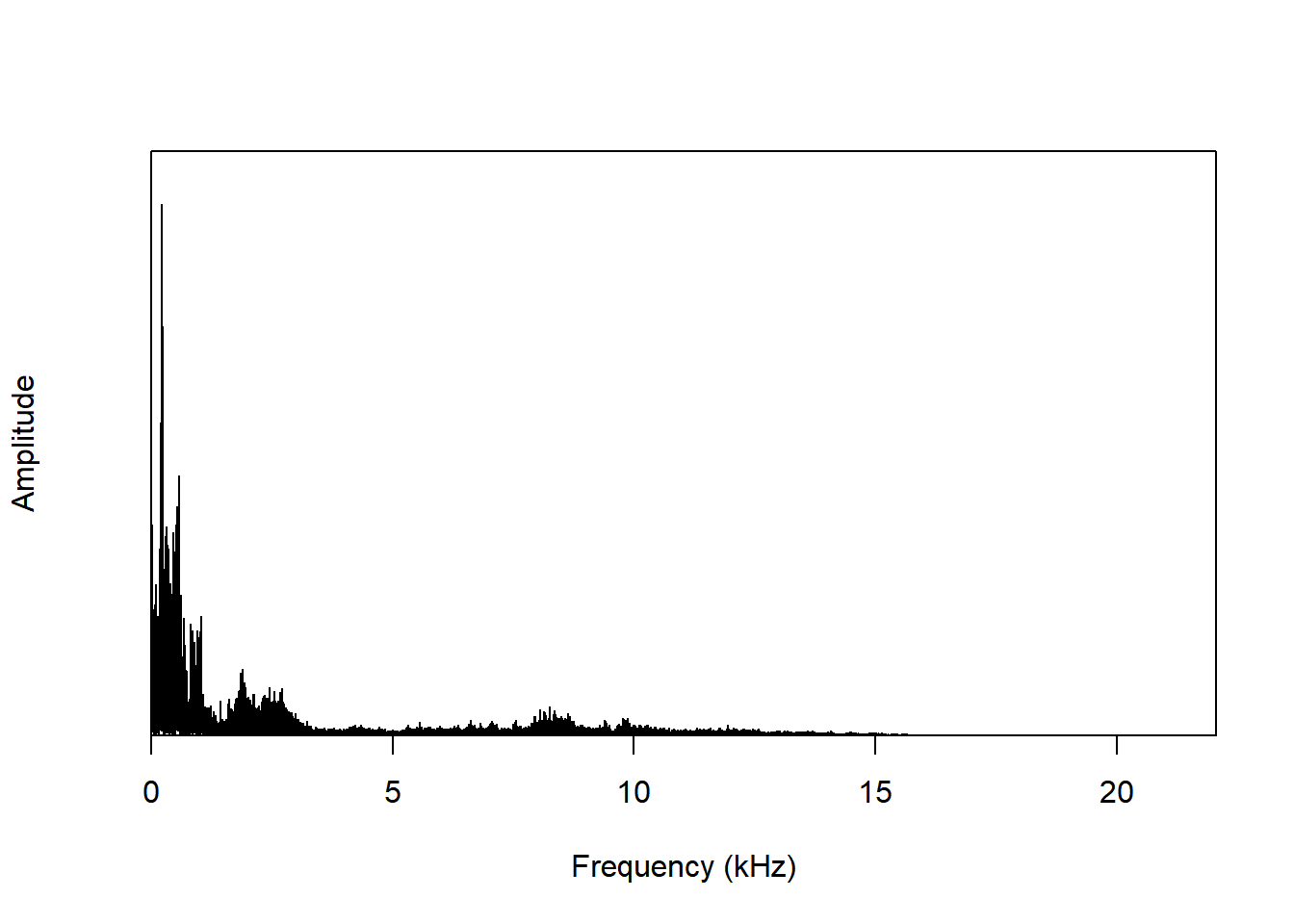
## an alpha between .9 and 1 is often used.
p2300.filter <- preemphasis(question1.2, alpha=.95,
output="Wave", plot=FALSE)
listen(p2300.filter)Another method to remove noise is to use the smoothing filter.
## wl is the window length
p2300.smooth <- smoothw(question1.2, wl=4, output='Wave')
listen(p2300.smooth)The function rmnoise does the smoothing based on cubic smoothing spline.
p2300.smooth.spline <- rmnoise(question1.2, output="Wave", spar=0.4)
listen(p2300.smooth)6.5 Speech transcription
6.5.1 Microsoft cognitive service
Microsoft cognitive service also provides API for speech transcription and recognition. The basic API currently supports two types of audio data no longer than 10 seconds:
- 16-bit 16kHz mono WAV in PCM format
- 16-bit 16kHz mono OGG in OPUS format
For longer audio files, the Batch Transcription API should be used, which supports the following formats. But the Batch Transcription API is not free.
| Format | Codec | Bitrate | Sample Rate |
|---|---|---|---|
| WAV | PCM | 16-bit | 8 or 16 kHz, mono, stereo |
| MP3 | PCM | 16-bit | 8 or 16 kHz, mono, stereo |
| OGG | OPUS | 16-bit | 8 or 16 kHz, mono, stereo |
We first try out the basic API. The audio recording from the mp3 file, therefore, needs to be download-sampled.
## we cut one minute of audio
question1 <- extractWave(p2300, 21, 25, xunit="time")
question1
##
## Wave Object
## Number of Samples: 176401
## Duration (seconds): 4
## Samplingrate (Hertz): 44100
## Channels (Mono/Stereo): Stereo
## PCM (integer format): TRUE
## Bit (8/16/24/32/64): 16
## downsample the data
question1 <- mono(question1, 'left')
question1 <- downsample(question1, 16000)
question1
##
## Wave Object
## Number of Samples: 64001
## Duration (seconds): 4
## Samplingrate (Hertz): 16000
## Channels (Mono/Stereo): Mono
## PCM (integer format): TRUE
## Bit (8/16/24/32/64): 16
## save data
## we have to use the audio package here
## the data will be changed to real format
question1.audio <- audioSample(question1@left, rate=16000)
save.wave(question1.audio, 'data/question2.wav')speech.api.key <- "3fe6addd690f469796fdfe6249532704"speech.file <- upload_file('data/question2.wav')
apiurl <- "https://westus.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&format=detailed"
question1.json.out <- POST(apiurl,
add_headers(`Ocp-Apim-Subscription-Key` = speech.api.key,
`Content-Type` = "audio/wav; samplerate=16000",
`Accept` = "application/json",
`Transfer-Encoding` = "chunked",
`Expect` = "100-continue"),
body = speech.file
)
question1.json.out
## Response [https://westus.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&format=detailed]
## Date: 2019-04-08 21:11
## Status: 200
## Content-Type: application/json; charset=utf-8
## Size: 1.86 kB
str(question1.json.out)
## List of 10
## $ url : chr "https://westus.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&format=detailed"
## $ status_code: int 200
## $ headers :List of 5
## ..$ date : chr "Mon, 08 Apr 2019 21:11:20 GMT"
## ..$ content-type : chr "application/json; charset=utf-8"
## ..$ server : chr "Kestrel"
## ..$ content-length : chr "1863"
## ..$ strict-transport-security: chr "max-age=31536000; includeSubDomains"
## ..- attr(*, "class")= chr [1:2] "insensitive" "list"
## $ all_headers:List of 1
## ..$ :List of 3
## .. ..$ status : int 200
## .. ..$ version: chr "HTTP/1.1"
## .. ..$ headers:List of 5
## .. .. ..$ date : chr "Mon, 08 Apr 2019 21:11:20 GMT"
## .. .. ..$ content-type : chr "application/json; charset=utf-8"
## .. .. ..$ server : chr "Kestrel"
## .. .. ..$ content-length : chr "1863"
## .. .. ..$ strict-transport-security: chr "max-age=31536000; includeSubDomains"
## .. .. ..- attr(*, "class")= chr [1:2] "insensitive" "list"
## $ cookies :'data.frame': 0 obs. of 7 variables:
## ..$ domain : logi(0)
## ..$ flag : logi(0)
## ..$ path : logi(0)
## ..$ secure : logi(0)
## ..$ expiration: 'POSIXct' num(0)
## ..$ name : logi(0)
## ..$ value : logi(0)
## $ content : raw [1:1863] 7b 22 52 65 ...
## $ date : POSIXct[1:1], format: "2019-04-08 21:11:20"
## $ times : Named num [1:6] 0 0.109 0.172 0.312 0.312 ...
## ..- attr(*, "names")= chr [1:6] "redirect" "namelookup" "connect" "pretransfer" ...
## $ request :List of 7
## ..$ method : chr "POST"
## ..$ url : chr "https://westus.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&format=detailed"
## ..$ headers : Named chr [1:5] "3fe6addd690f469796fdfe6249532704" "audio/wav; samplerate=16000" "application/json" "chunked" ...
## .. ..- attr(*, "names")= chr [1:5] "Ocp-Apim-Subscription-Key" "Content-Type" "Accept" "Transfer-Encoding" ...
## ..$ fields : NULL
## ..$ options :List of 6
## .. ..$ useragent : chr "libcurl/7.59.0 r-curl/3.3 httr/1.4.0"
## .. ..$ cainfo : chr "C:/PROGRA~1/R/R-35~1.2/etc/curl-ca-bundle.crt"
## .. ..$ http_version : num 0
## .. ..$ post : logi TRUE
## .. ..$ readfunction :function (nbytes, ...)
## .. ..$ postfieldsize_large: num 128046
## ..$ auth_token: NULL
## ..$ output : list()
## .. ..- attr(*, "class")= chr [1:2] "write_memory" "write_function"
## ..- attr(*, "class")= chr "request"
## $ handle :Class 'curl_handle' <externalptr>
## - attr(*, "class")= chr "response"
question1.txt <- question1.json.out %>%
content()
question1.txt
## $RecognitionStatus
## [1] "Success"
##
## $Offset
## [1] 700000
##
## $Duration
## [1] 39100000
##
## $NBest
## $NBest[[1]]
## $NBest[[1]]$Confidence
## [1] 0.9224742
##
## $NBest[[1]]$Lexical
## [1] "we think of a specific time that you felt happy and tell me about it"
##
## $NBest[[1]]$ITN
## [1] "we think of a specific time that you felt happy and tell me about it"
##
## $NBest[[1]]$MaskedITN
## [1] "we think of a specific time that you felt happy and tell me about it"
##
## $NBest[[1]]$Display
## [1] "We think of a specific time that you felt happy and tell me about it."
##
##
## $NBest[[2]]
## $NBest[[2]]$Confidence
## [1] 0.8322114
##
## $NBest[[2]]$Lexical
## [1] "think of a specific time that you felt happy and tell me about it"
##
## $NBest[[2]]$ITN
## [1] "think of a specific time that you felt happy and tell me about it"
##
## $NBest[[2]]$MaskedITN
## [1] "think of a specific time that you felt happy and tell me about it"
##
## $NBest[[2]]$Display
## [1] "Think of a specific time that you felt happy and tell me about it."
##
##
## $NBest[[3]]
## $NBest[[3]]$Confidence
## [1] 0.8347502
##
## $NBest[[3]]$Lexical
## [1] "maybe think of a specific time that you felt happy and tell me about it"
##
## $NBest[[3]]$ITN
## [1] "maybe think of a specific time that you felt happy and tell me about it"
##
## $NBest[[3]]$MaskedITN
## [1] "maybe think of a specific time that you felt happy and tell me about it"
##
## $NBest[[3]]$Display
## [1] "Maybe think of a specific time that you felt happy and tell me about it."
##
##
## $NBest[[4]]
## $NBest[[4]]$Confidence
## [1] 0.8200455
##
## $NBest[[4]]$Lexical
## [1] "be think of a specific time that you felt happy and tell me about it"
##
## $NBest[[4]]$ITN
## [1] "be think of a specific time that you felt happy and tell me about it"
##
## $NBest[[4]]$MaskedITN
## [1] "be think of a specific time that you felt happy and tell me about it"
##
## $NBest[[4]]$Display
## [1] "Be think of a specific time that you felt happy and tell me about it."
##
##
## $NBest[[5]]
## $NBest[[5]]$Confidence
## [1] 0.8222597
##
## $NBest[[5]]$Lexical
## [1] "he think of a specific time that you felt happy and tell me about it"
##
## $NBest[[5]]$ITN
## [1] "he think of a specific time that you felt happy and tell me about it"
##
## $NBest[[5]]$MaskedITN
## [1] "he think of a specific time that you felt happy and tell me about it"
##
## $NBest[[5]]$Display
## [1] "He think of a specific time that you felt happy and tell me about it."6.5.2 Google Cloud Speech-to-Text
Google Cloud Speech-to-Text converts audio to text based on powerful neural network models. It also provides more options than Microsoft cognitive service.
We illustrate how to use the service using the R package googleLanguageR.
library(googleLanguageR)
## user information
gl_auth('misc/google.json')
## prepare data, an audio file less than 60 seconds
question2 <- extractWave(p2300, 22, 71, xunit="time")
question2
##
## Wave Object
## Number of Samples: 2160901
## Duration (seconds): 49
## Samplingrate (Hertz): 44100
## Channels (Mono/Stereo): Stereo
## PCM (integer format): TRUE
## Bit (8/16/24/32/64): 16
question2 <- mono(question2, 'left')
question2 <- downsample(question2, 16000)
question2.audio <- audioSample(question2@left, rate=16000)
save.wave(question2.audio, 'data/question2.wav')
## send the audio file for transcription
result <- gl_speech("data/question2.wav")
result$transcript
## # A tibble: 4 x 2
## transcript confidence
## <chr> <chr>
## 1 specific time that you felt happy and tell me about it by specific~ 0.958813
## 2 " I got a new job" 0.985991
## 3 " tell me one time you felt sorry" 0.9827167
## 4 " I put my foot in my mouth and said something hurtful or hurtful ~ 0.93259317For large audio files, they have to be saved on Google cloud storage.
p2300.m <- mono(p2300, 'left')
p2300.m <- downsample(p2300.m, 16000)
p2300.m.audio <- audioSample(p2300.m@left, rate=16000)
save.wave(p2300.m.audio, 'data/p2300.wav')
result <- gl_speech("gs://rdatascience/p2300.wav", sampleRateHertz = 16000L, asynch = TRUE)
text <- gl_speech_op(result)
paste0(text$transcript$transcript, collapse = "|")
## [1] ""> text <- gl_speech_op(result)
2019-02-19 08:21:20 -- Asychronous transcription finished.
> paste0(text$transcript$transcript, collapse = "|")
[1] "this is participant number 2300 this is a one-year assessment I am examiner 606 and today's date is 8-27-2018 I'm going to be asking to think of times from your past when you felt certain ways I'd like you to tell me about those times we're going to start with happy think of a specific time that you felt happy and tell me about it by specific I mean one memory from your past that happened in a single day|I got a new job| tell me one time you felt sorry| am I put my foot in my mouth and said something hurtful or hurtful to my thirteen-year-old without realizing that she would even take it in that way and then once I realized and played it back in my mind and thought about it| being perceived by a 13 year old I seen where where she could have taken it the wrong way and it made me feel sorry and I'm sitting thing tell me what time you felt safe| Quake Mario was here with us to be honest| I got home from work after working a long day being busy all day and| he and my son had cleaned my entire house and cook dinner and it definitely made me feel safe and warm and comfortable okay tell me one time you felt angry| my daughter was being dishonest and I| chilled and block them from social media and I found out that she was entertaining conversations on social media and being online after hours when she was supposed to be asleep and it made me feel very angry| tell me what time you felt interested| I love to read and I love to learn so what I went to school for is esthetician I felt very interested when I found out that there is a medical certification that comes with that cuz I originally wanted to go to school for something in the medical field so it coincide with the medical field and what I actually went to school for| one time you felt clumsy| we had company at our house and I fell up the stairs not down them| so sometimes our equilibrium can get thrown off when you're carrying clothes and multitasking and I felt stairs okay what time you felt successful| writing down a list of challenges for myself I do it on a monthly basis at the start of every month I go back and I see if I've surpassed my goals if I've just made it or if it was something that got pushed pushed to the bottom of the barrel and I didn't work on it at all and quite a few times I've been able to look back and see that I hit every goal that I tried LOL so that help very successful yes| tell me one time that you felt hurt and these are your feelings| when my daughter told me she didn't want to come back home and go to school here I thought we're hurt| cuz she doesn't call very often she only calls when she wants something but you know you'll have that at 13| what time you felt surprised| Aiden drew me a picture at preschool| and it was perfect I was very surprised that he would be able that he was able to be that creative at such a young age he drew me a picture of a butterfly and I didn't think it was going to look like a butterfly when he told me what it was cuz I know there that I love butterflies but I was surprised he did a very good job I hate| about what time you felt lonely| for a while when Aiden's dad left I felt lonely| just cuz I had a new baby we had planned our| pregnancy and getting married and stuff and you know once we broke up he relocated and| I just kind of felt lonely as a new mom| okay but thank you for sharing and you doing difficult but"