Chapter 7 Video data
7.1 Video format [from Wikipedia]
A video file format is a type of file format for storing digital video data on a computer system. Video is almost always stored using lossy compression to reduce the file size.
A video file typically consists of a container (e.g., MPEG-4) containing video data in a video coding format (e.g., H.264) alongside audio data in an audio coding format (e.g., mp3). The container can also contain synchronization information, subtitles, and metadata such as title. A standardized (or in some cases de facto standard) video file type such as .webm (e.g., used in YouTube) is a profile specified by a restriction on which container format and which video and audio compression formats are allowed.
The coded video and audio inside a video file container are called the essence. A program (or hardware) which can decode compressed video or audio is called a codec; playing or encoding a video file will sometimes require the user to install a codec library corresponding to the type of video and audio coding used in the file.
Good design dictates typically that a file extension enables the user to derive which program will open the file from the file extension. That is the case with some video file formats, such as WebM (.webm), Windows Media Video (.wmv), Flash Video (.flv), and Ogg Video (.ogv), each of which can only contain a few well-defined subtypes of video and audio coding formats, making it relatively easy to know which codec will play the file. In contrast to that, some very general-purpose container types like AVI (.avi) and QuickTime (.mov) can contain video and audio in almost any format, and have file extensions named after the container type, making it very hard for the end user to use the file extension to derive which codec or program to use to play the files.
The free software FFmpeg project’s libraries have extensive support for encoding and decoding video file formats. For example, Google uses FFmpeg to support a wide range of upload video formats for YouTube. One widely used media player using the FFmpeg libraries is the free software VLC media player, which can play most video files that end users will encounter.
7.2 Read video data into R
To handle the video data using R, we need to install ffmpeg, a complete, cross-platform solution to record, convert and stream audio and video. It includes libavcodec - the leading audio/video codec library. We have to put the program on the search path. Since we cannot modify the system path directly, we copy the FFmpeg file to this folder (change xxxx to your user name):
C:\Users\xxxx\AppData\Local\Microsoft\WindowsAppsWe will use the file debate.mp4 as an example. It was downloaded from YouTube with information on the debate between Trump and Clinton.
The basic information about a video can be obtained using the FFmpeg program.
system('ffmpeg -hide_banner -i data/debate.mp4')-hide_banner: skip the basic information of FFmpeg-i: specify the input file
Loading a video into R can take a lot of memory. For example, for the 5 minutes video, it would use more than 30Gb of memory.
debate <- load.video('debate.mp4')For demonstration, we select 15 seconds of the video and then load it into R. Here, we directly use the ffmpeg program to subset the video but within R.
cmd <- 'ffmpeg -hide_banner -y -loglevel panic -ss 00:00:14 -i data/debate.mp4 -to 00:00:15 -c copy data/debate15.mp4'
system(cmd)-hide_banner: do not show the basic ffmpeg information-y: overwrite the existing file-loglevel: how much log information to show. panic: not show at all.-i: This specifies the input file. In this case, it is debate.mp4.-ss: Used with -i, this seeks in the input file to position. 00:00:00: This is the time your trimmed video will start with. The timing format is: hh:mm:ss-to: This specifies duration from start (00:00:14) to end (00:00:14+00:00:15). 00:00:15: This is the time duration your trimmed video will end with.-c copy: This is an option to trim via stream copy.
Note that only 15 seconds of video already took about 2Gb of memory. In the following, maxSize specifies the max amount of memory to be used.
debate <- load.video('data/debate15.mp4', maxSize=2)
format(object.size(debate), 'Mb')
## [1] "1977.5 Mb"
debate
## Image. Width: 640 pix Height: 360 pix Depth: 375 Colour channels: 3We could also load a part of the video using the load.video function directly. The following code would load 300 frames from the 14th second.
test <- load.video('data/debate.mp4', maxSize=2,
skip.to = "00:00:14", frames=300)
test
## Image. Width: 640 pix Height: 360 pix Depth: 300 Colour channels: 3There are a total of 375 frames in the video (Depth = 375). The debate object includes a four dimensional array.
To plot a frame, we use
plot(debate, frame=1)
plot(debate, frame=50)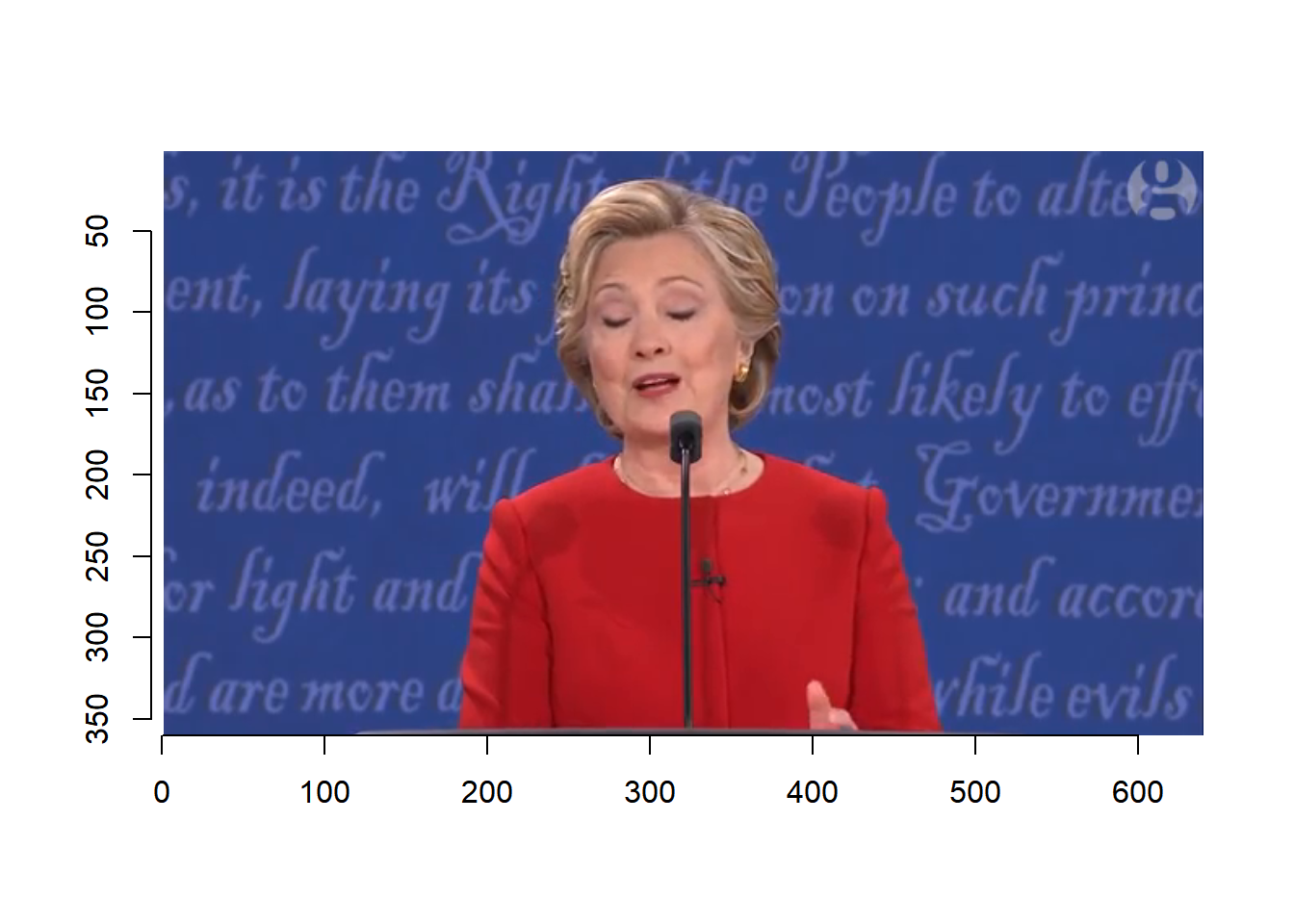
To play the video, we use
imager::play(debate)To access a frame of the video, use
frame(debate, 10)
## Image. Width: 640 pix Height: 360 pix Depth: 1 Colour channels: 3To save a frame to an image file, use
save.image(frame(debate,40), 'data/frame40.jpg')
save.image(frame(debate,40), 'data/frame40.png')7.2.1 Find keyframes
We can plot a given number of frames at a time and then select the keyframes. We can plot each frame one by one.
for (i in seq(1, 375, 50)){
plot(debate, frame=i)
readline(prompt=paste("Frame ", i, "Press [enter] to continue"))
}
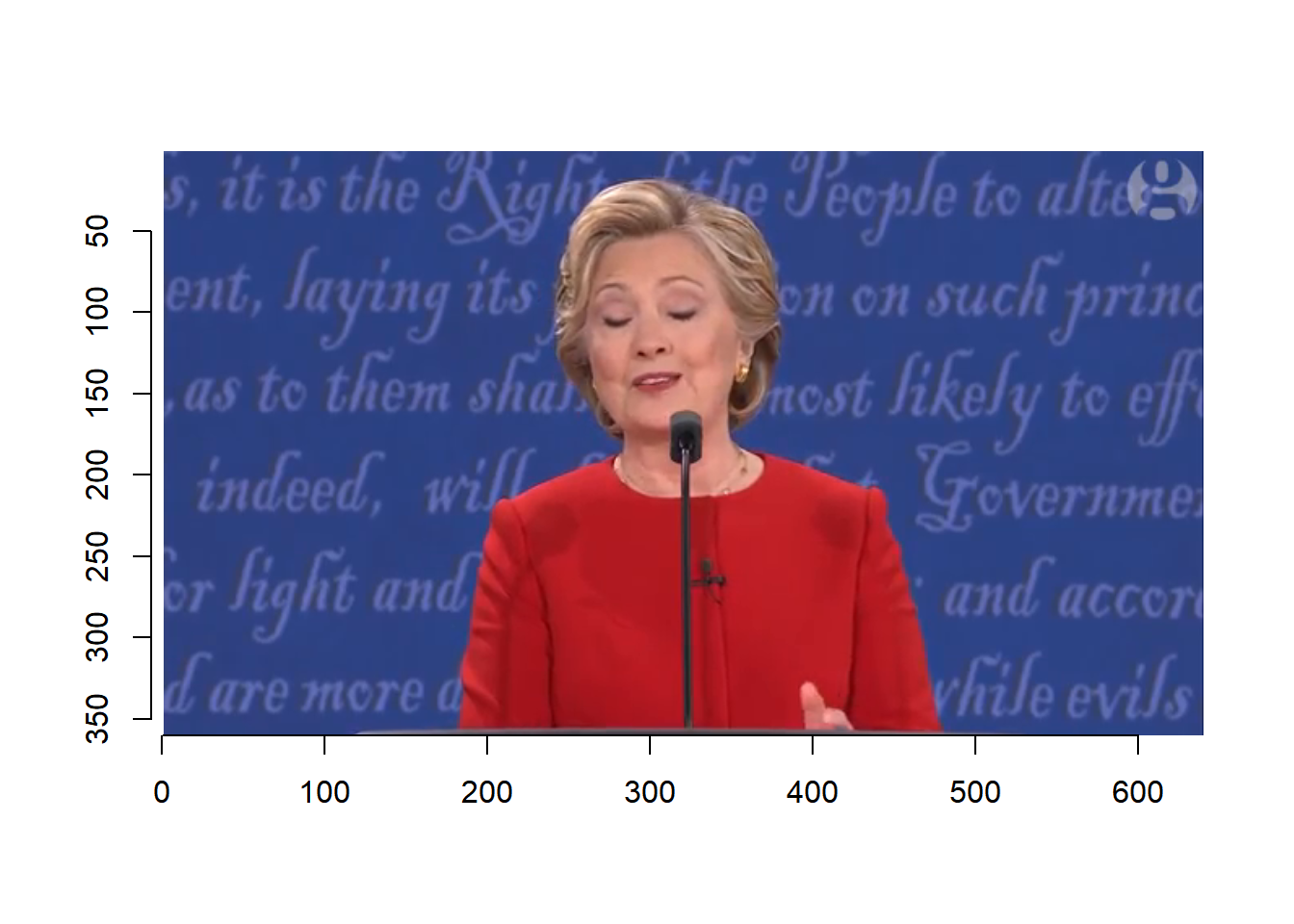
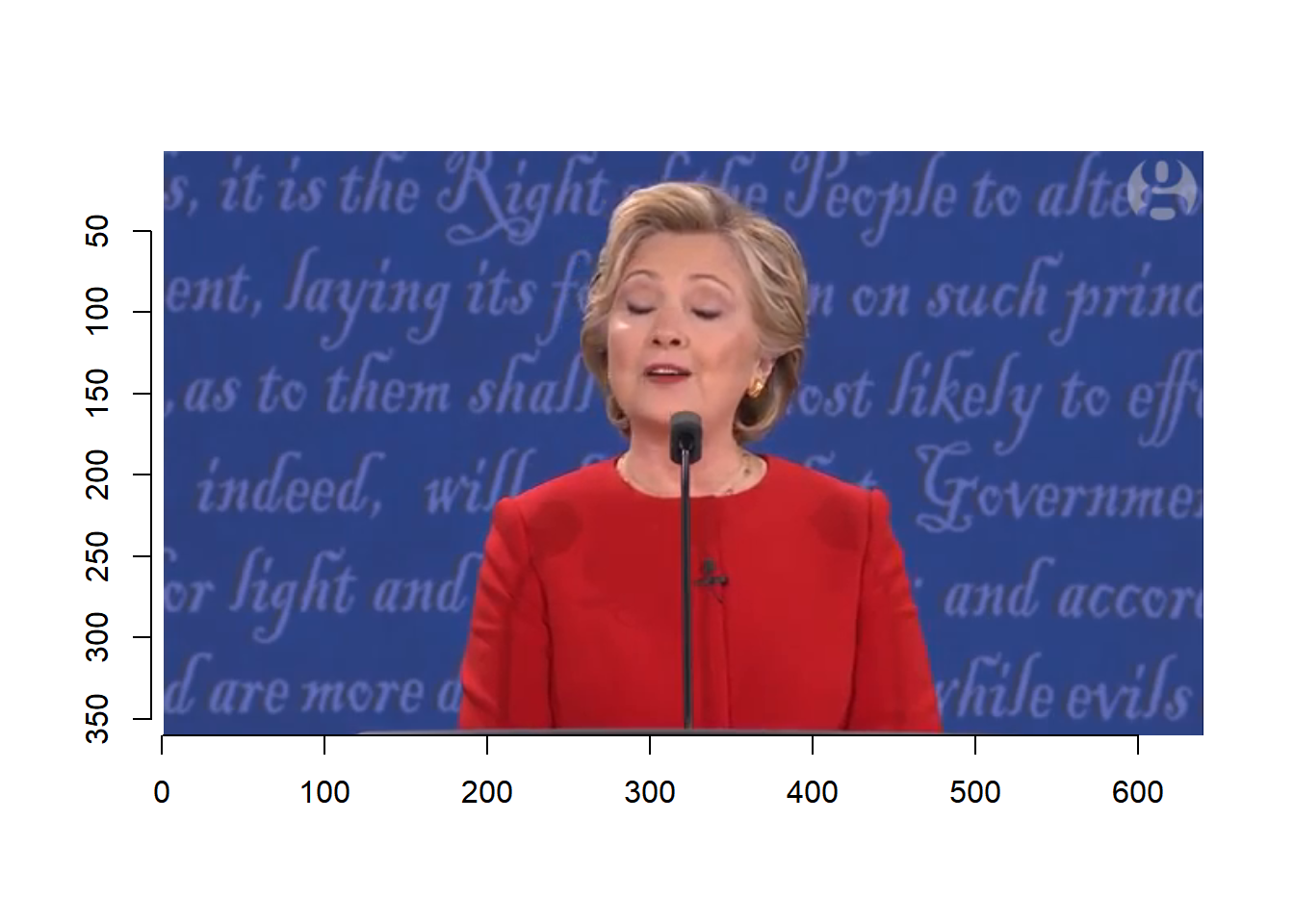
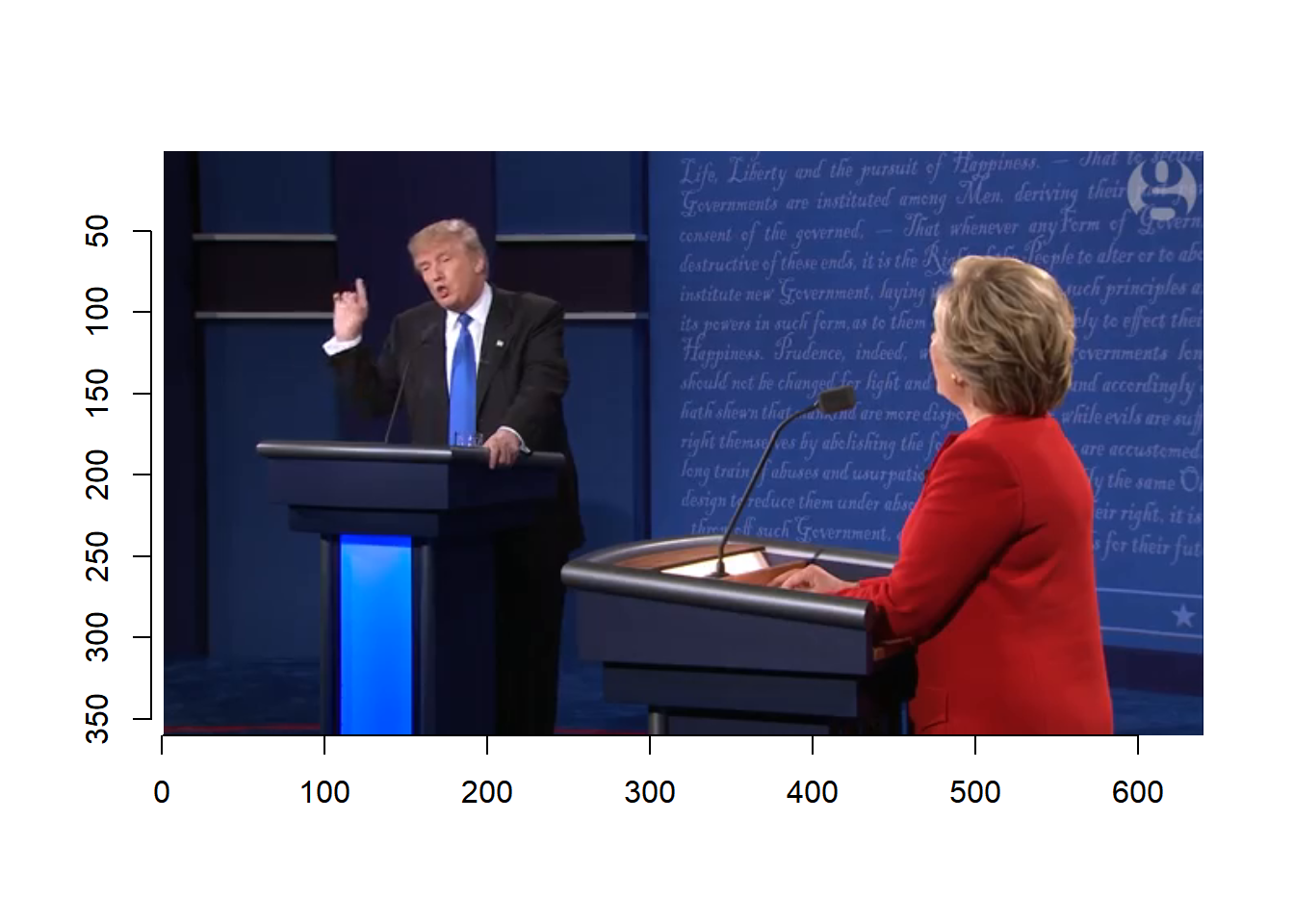
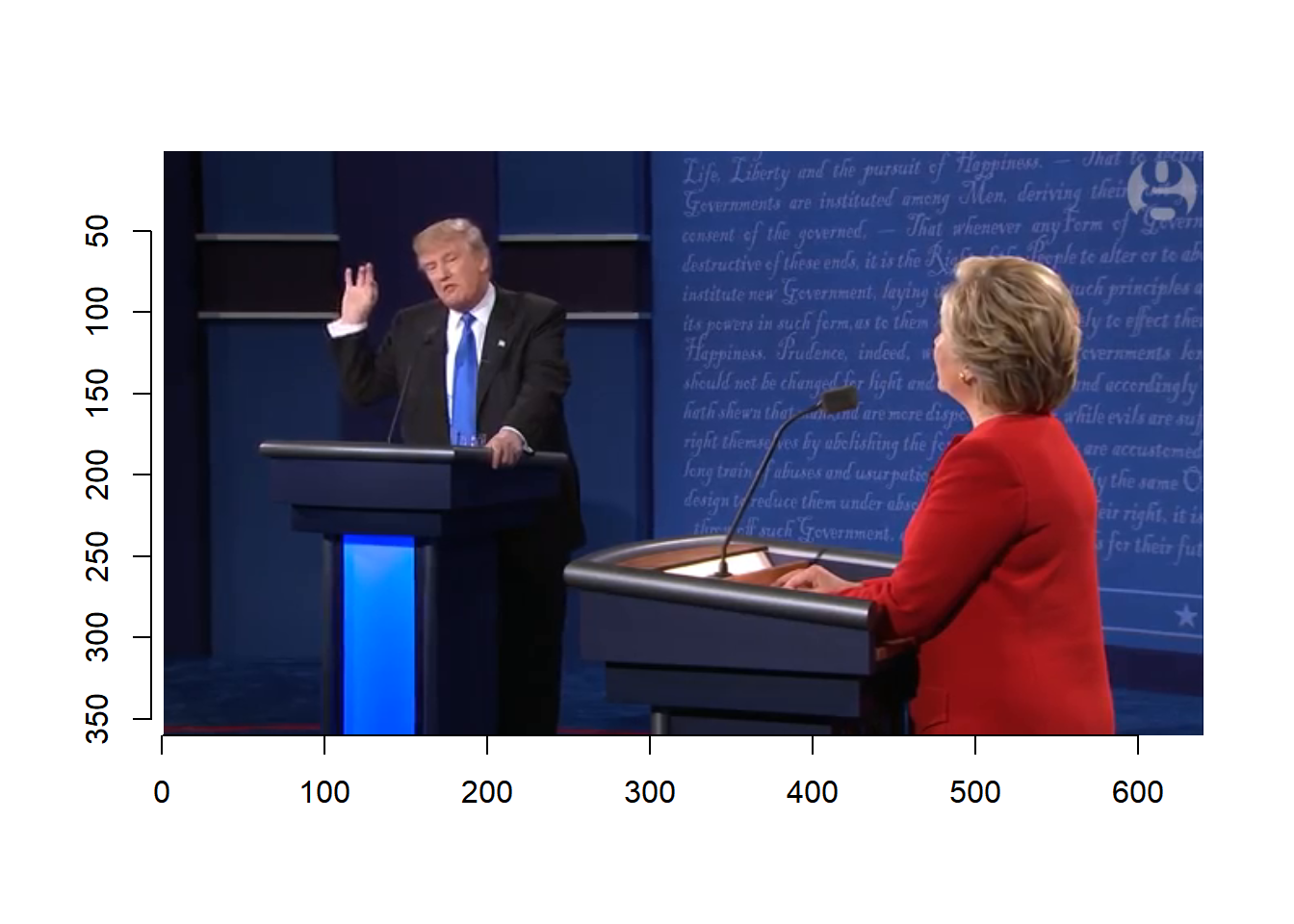
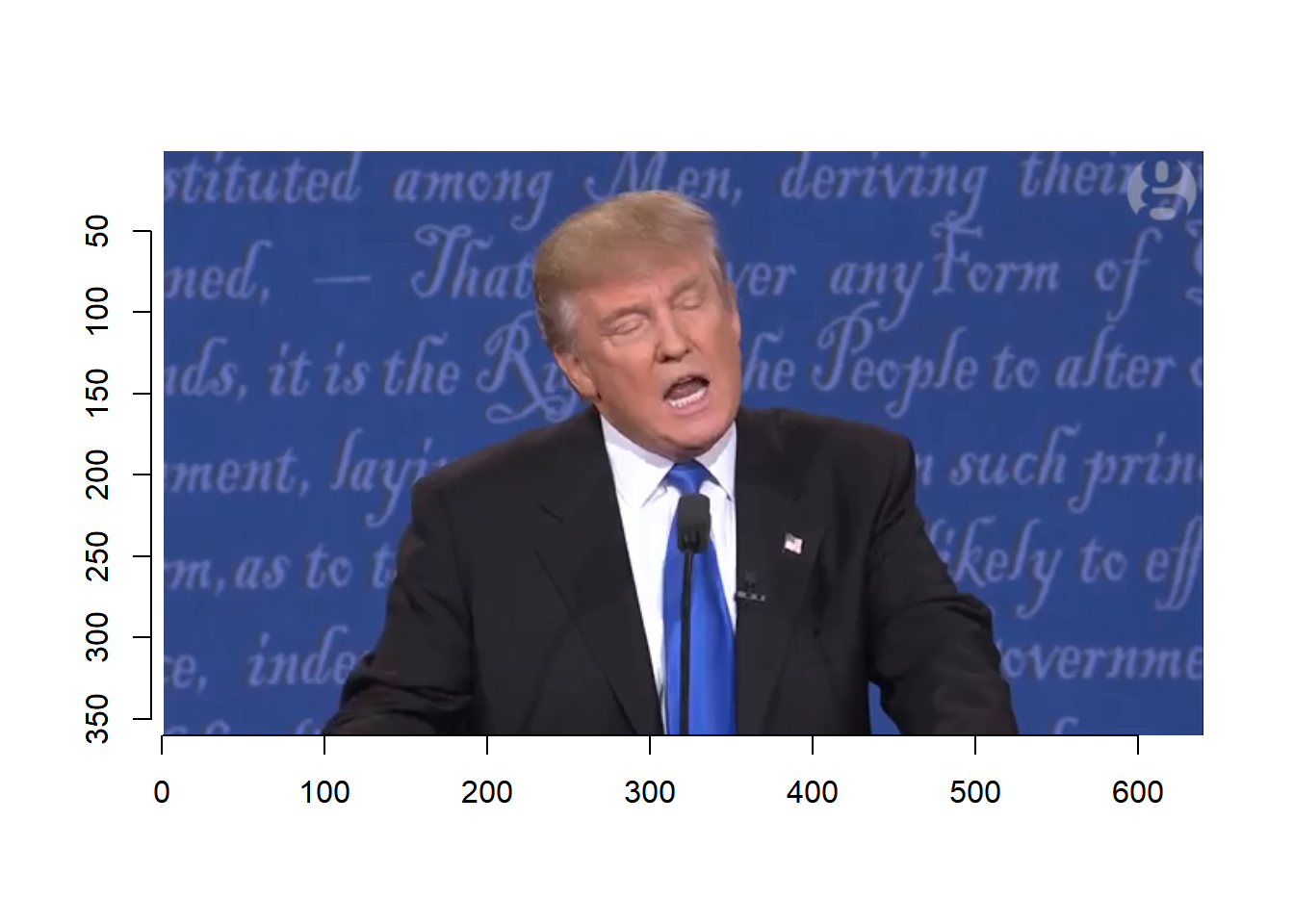
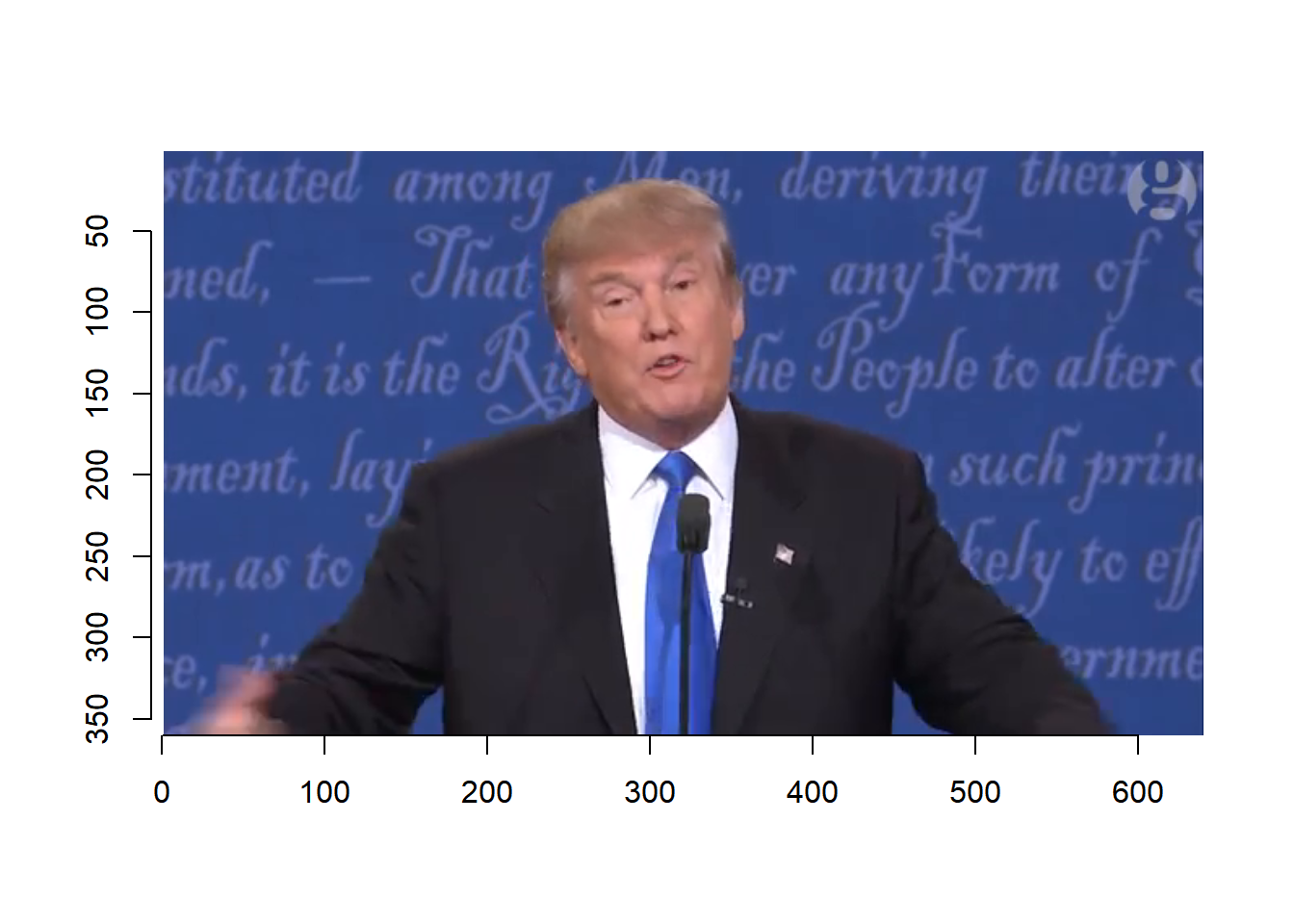
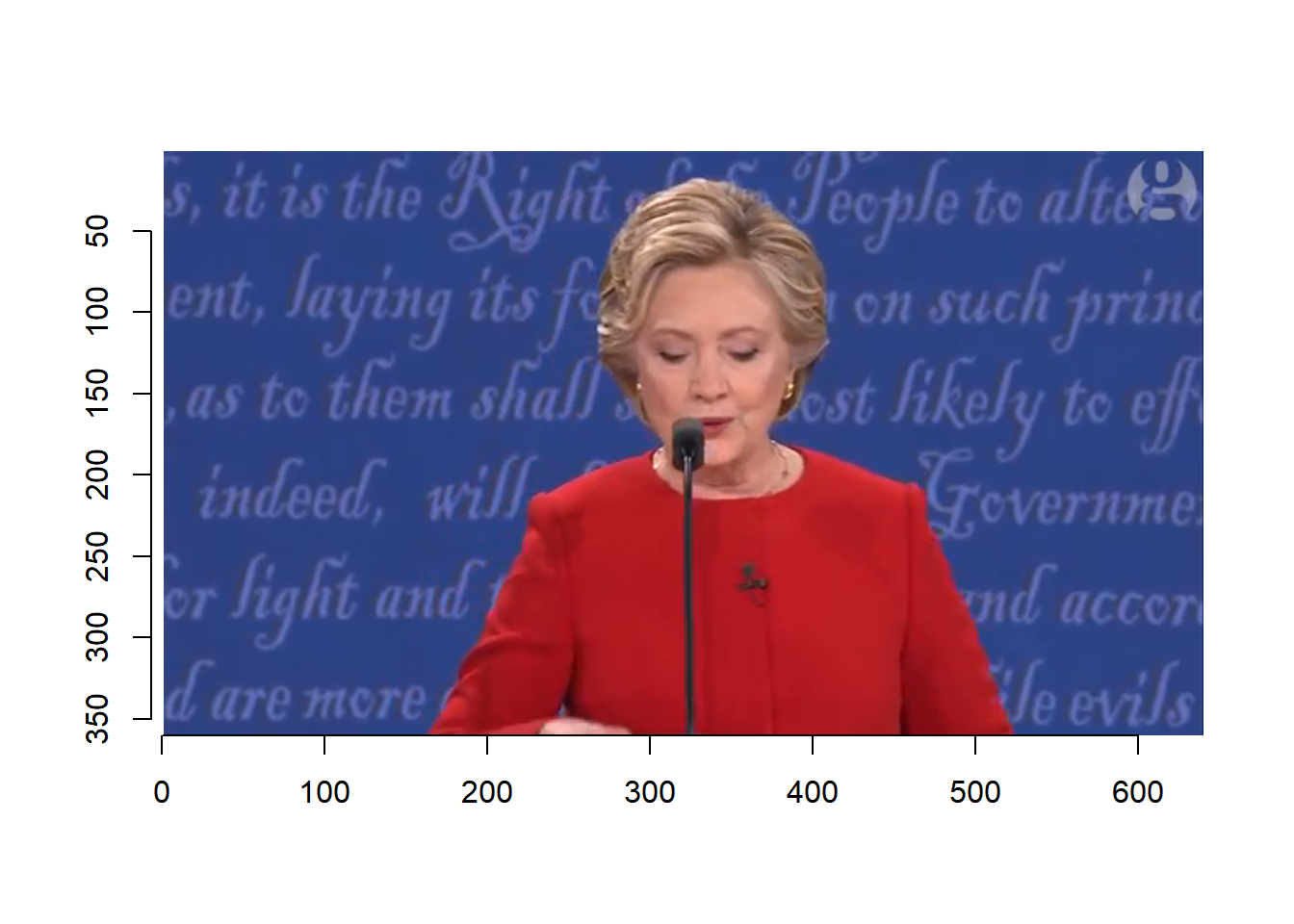
Based on the video, we select the following frames.
trump.key.frame <- c(251, 261, 271, 281, 291, 301, 311, 321, 331)
clinton.key.frame <- c(21, 31, 41, 51, 61, 71, 81, 91, 101, 341, 351, 361, 371)7.2.2 Emotion detection
After identifying the keyframes, we can get the emotion of the face in it through Microsoft Cognitive API.
facekey <- "5b336abc1ae94484a21cead03baedccc"
apiurl <- "https://westus.api.cognitive.microsoft.com/face/v1.0/detect?returnFaceId=true&returnFaceLandmarks=true&returnFaceAttributes=emotion"
trump.emotion <- NULL
for (index in trump.key.frame){
## save the frame to an image file
image.file.name <- paste0('data/frame', index, '.jpg')
save.image(frame(debate,index), image.file.name)
emotion.face <- upload_file(image.file.name)
emotion.json.out <- POST(apiurl,
add_headers(`Ocp-Apim-Subscription-Key` = facekey,
`Content-Type` = "application/octet-stream"),
body = emotion.face
)
emotion.face.out <- emotion.json.out %>%
content()
trump.emotion <- rbind(trump.emotion,
unlist(emotion.face.out[[1]]$faceAttributes$emotion))
}
trump.emotion
## anger contempt disgust fear happiness neutral sadness surprise
## [1,] 0.559 0.001 0.027 0.012 0.005 0.147 0.142 0.107
## [2,] 0.249 0.030 0.051 0.001 0.002 0.631 0.027 0.008
## [3,] 0.012 0.011 0.011 0.002 0.004 0.905 0.022 0.033
## [4,] 0.008 0.041 0.024 0.001 0.008 0.815 0.082 0.019
## [5,] 0.039 0.001 0.013 0.002 0.004 0.649 0.277 0.015
## [6,] 0.000 0.030 0.000 0.000 0.001 0.961 0.006 0.001
## [7,] 0.067 0.007 0.006 0.000 0.002 0.761 0.001 0.157
## [8,] 0.013 0.004 0.014 0.000 0.001 0.959 0.008 0.001
## [9,] 0.000 0.001 0.000 0.000 0.000 0.996 0.003 0.000
plot.data <- trump.emotion %>% as_tibble %>%
gather("type", "value") %>%
mutate(type = as.factor(type)) %>%
mutate(time=rep(1:8, each=9), id=rep(1:9, 8))
plot.data %>%
ggplot(aes(time, value, group=id, color=id))+
geom_point(aes(shape=type))+
geom_line()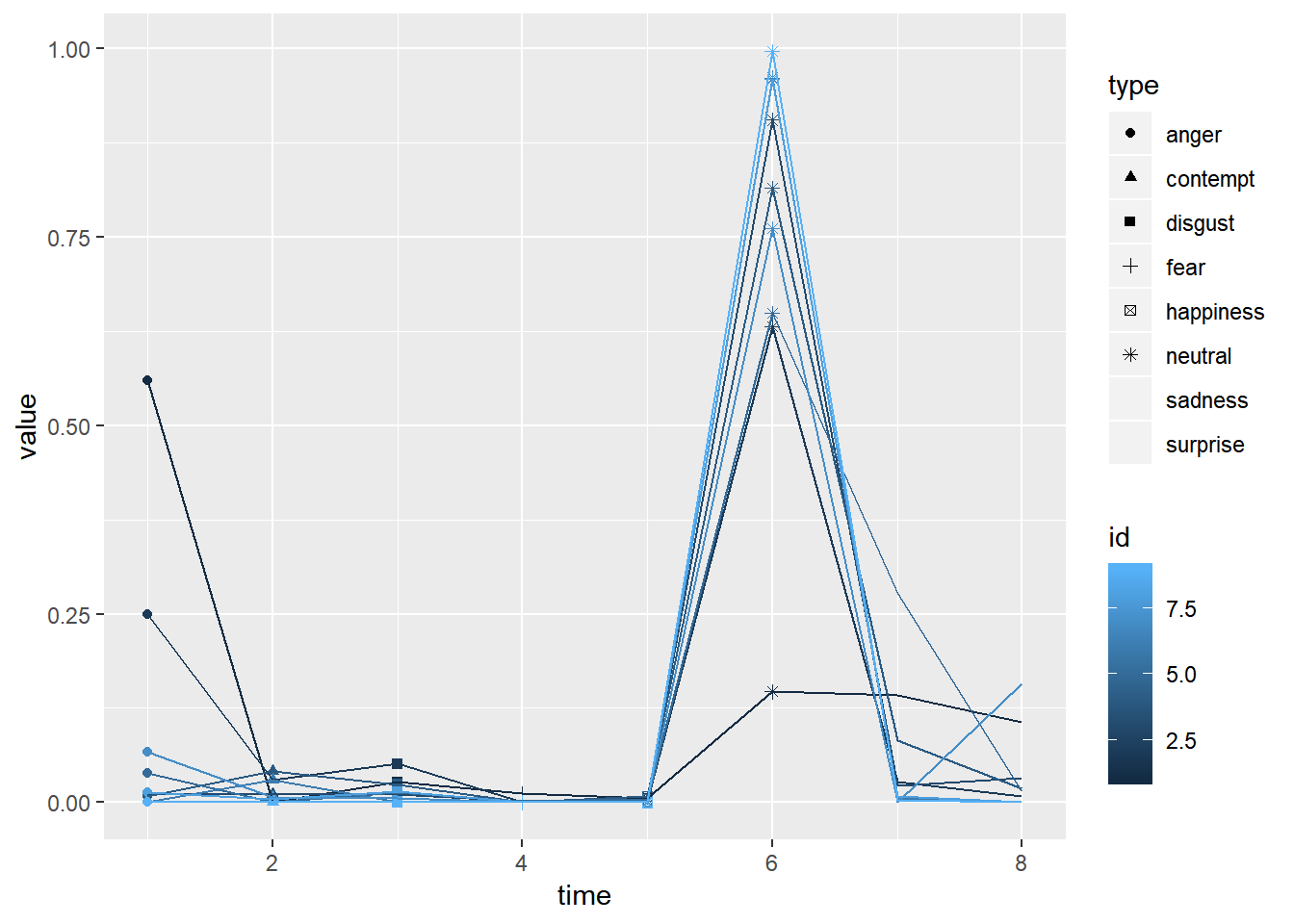
7.2.3 Practice
Now select some keyframes for Clinton and identify her emotion.
facekey <- "5b336abc1ae94484a21cead03baedccc"
apiurl <- "https://westus.api.cognitive.microsoft.com/face/v1.0/detect?returnFaceId=true&returnFaceLandmarks=true&returnFaceAttributes=emotion"
clinton.emotion <- NULL
for (index in clinton.key.frame){
## save the frame to an image file
image.file.name <- paste0('data/frame', index, '.jpg')
save.image(frame(debate,index), image.file.name)
emotion.face <- upload_file(image.file.name)
emotion.json.out <- POST(apiurl,
add_headers(`Ocp-Apim-Subscription-Key` = facekey,
`Content-Type` = "application/octet-stream"),
body = emotion.face
)
emotion.face.out <- emotion.json.out %>%
content()
clinton.emotion <- rbind(clinton.emotion,
unlist(emotion.face.out[[1]]$faceAttributes$emotion))
}
clinton.emotion
## anger contempt disgust fear happiness neutral sadness surprise
## [1,] 0 0.063 0 0 0.024 0.906 0.005 0.000
## [2,] 0 0.000 0 0 1.000 0.000 0.000 0.000
## [3,] 0 0.015 0 0 0.066 0.911 0.003 0.005
## [4,] 0 0.001 0 0 0.941 0.024 0.000 0.034
## [5,] 0 0.000 0 0 0.996 0.000 0.000 0.004
## [6,] 0 0.000 0 0 0.918 0.003 0.000 0.078
## [7,] 0 0.000 0 0 0.780 0.000 0.000 0.220
## [8,] 0 0.000 0 0 0.009 0.207 0.000 0.785
## [9,] 0 0.001 0 0 0.913 0.046 0.000 0.040
## [10,] 0 0.001 0 0 0.827 0.167 0.002 0.002
## [11,] 0 0.001 0 0 0.006 0.948 0.043 0.001
plot.data <- clinton.emotion %>% as_tibble %>%
gather("type", "value") %>%
mutate(type = as.factor(type)) %>%
mutate(time=rep(1:8, nrow(clinton.emotion)), id=rep(1:nrow(clinton.emotion), 8))
plot.data %>%
ggplot(aes(time, value, group=id, color=id))+
geom_point(aes(shape=type))+
geom_line()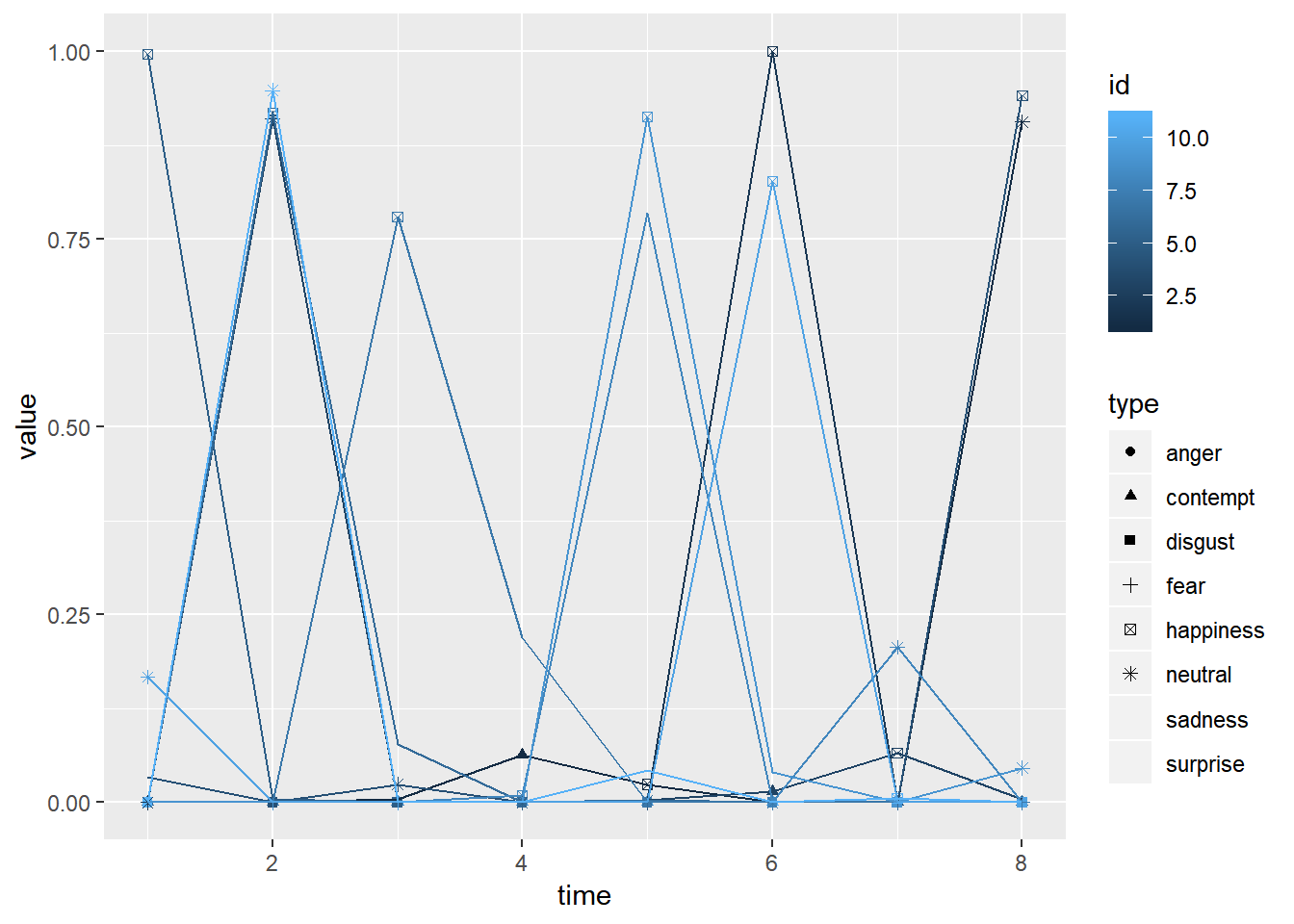
7.3 More sophisticated analysis
Microsoft video indexer can be used to analyze multiple perspectives of information in a video. For longer videos, it can be useful for quick analysis. It also provides an API so one can use it directly within R like the use of APIs for text and image analysis. Here, we directly use the website to index a video and then process the results within R. To use it, one needs to create an account. Some instruction can be found here: https://docs.microsoft.com/en-us/azure/media-services/video-indexer/video-indexer-use-apis
Once a video is uploaded, it will be processed by the server. The basic information is directly shown on the webpage as below. It includes:
- People appear in the video
- Topics of the video
- Keywords
- Labels
- Emotions
- Keyframes
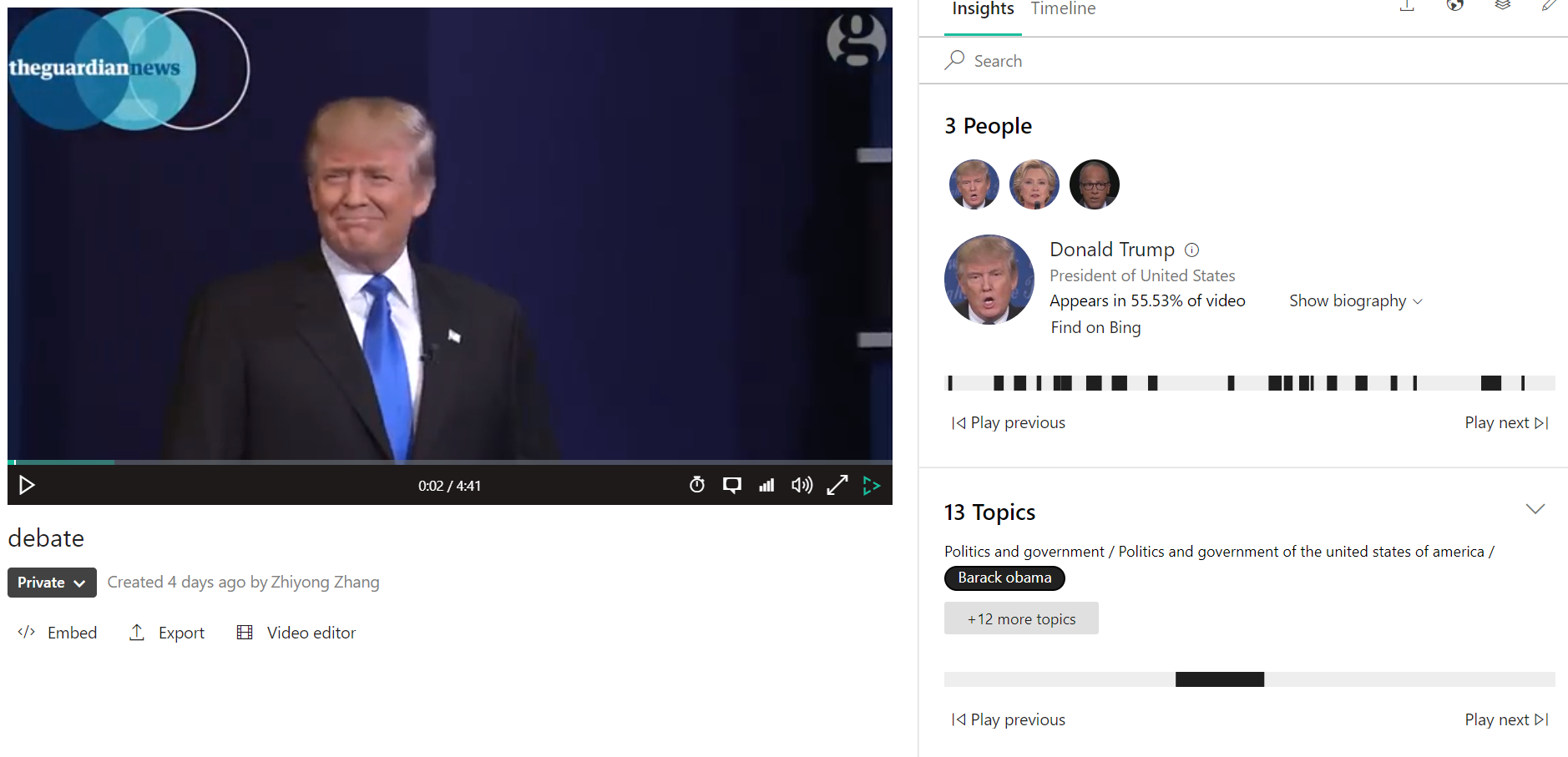
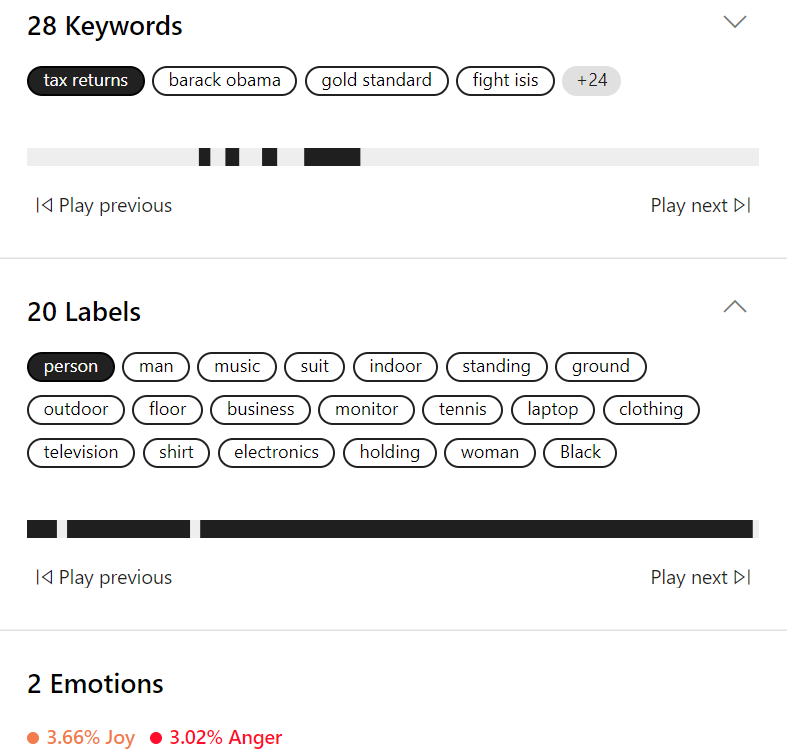
The information regarding the video can be downloaded as JSON files.
7.3.1 Insights
The basic information is included in the Insights (JSON) file - insights.json.
insights <- fromJSON('data/insights.json')The list of elements in it can be found at https://docs.microsoft.com/en-us/azure/media-services/video-indexer/video-indexer-output-json-v2.
7.3.1.1 Transcript
The audio transcript can be accessed.
transcript <- insights$videos$insights$transcript[[1]]
head(transcript)
## id
## 1 0
## 2 1
## 3 2
## 4 3
## 5 4
## 6 5
## text
## 1
## 2 was against it once it was finally negotiated and the terms were laid out.
## 3 I wrote about that in gold at the gold standard you.
## 4 Called it the gold standard of trails.
## 5 You said it's the finest deal.
## 6 You've ever seen no and then you heard what I said about it and all of a sudden you were against well.
## confidence speakerId language
## 1 1.0000 0 en-US
## 2 0.9152 1 en-US
## 3 0.9152 2 en-US
## 4 0.9152 2 en-US
## 5 0.9152 3 en-US
## 6 0.9152 3 en-US
## instances
## 1 0:00:00, 0:00:09, 0:00:00, 0:00:09, 0:00:09
## 2 0:00:09, 0:00:13.46, 0:00:09, 0:00:13.46, 0:00:04.46
## 3 0:00:13.46, 0:00:16.62, 0:00:13.46, 0:00:16.62, 0:00:03.16
## 4 0:00:16.62, 0:00:18.94, 0:00:16.62, 0:00:18.94, 0:00:02.32
## 5 0:00:18.94, 0:00:20.79, 0:00:18.94, 0:00:20.79, 0:00:01.85
## 6 0:00:20.79, 0:00:26.92, 0:00:20.79, 0:00:26.92, 0:00:06.13The data include the transcript text and the speakerId. Note that the identification of a speaker is not very accurate. But based on it, we can get the transcript for each speaker.
speaker2 <- paste0(transcript$text[transcript$speakerId==2], collapse = " ")
speaker2
## [1] "I wrote about that in gold at the gold standard you. Called it the gold standard of trails. Donald I know you live in your own reality. But that is not the fact and look at her website. too much. The next segment. We're continuing the subject of a plan to fight no. No wonder you been fighting isys your entire adult life. That 's a That's go to that place the fact Checkers Galjour, I think you've just seen. Another example of bait and switch here. So you've got to ask yourself. Why won't, he release his tax returns and I think there may be a couple of reasons. First, maybe he's not as rich as he says he is second. Maybe. Charitable as he claims to be or maybe he doesn't want the American people. All of you watching tonight to know that he's paid nothing in federal taxes because the only years that anybody's ever seen where a couple of years when he had to turn them over to state authorities when he was trying to get a casino license and they showed he didn't pay any federal income tax so he has a long record of engaging in racist behavior. Arthur lie was a very hurtful one you know, Barack Obama is a man of great dignity. An I could tell how much it bothered him and annoyed him that this was being touted and used against him. First of all. I got to watch in preparing for this some of your debates against Barack Obama. I said she doesn't have the stamina and I don't believe she does have the stamina to be president of this country. You need tremendous stamina well as soon as he travels to 112 countries in negotiates a peace deal. A cease fire a release of dissidents and opening of new opportunities and. The world or even spends 11 hours testifying in front of a congressional committee he can talk to me about stamina the world. But it's bad bad experience. You know, he tried to switch from from looks to stamina, but this is a man. Women Pigs Slobs and dogs by thanks to Hillary Clinton and Donald Trump and to Hofstra University for hosting us tonight,"7.3.1.2 Sentiment
Three sentiment types, Positive/Neutral/Negative, are scored. It also has information on the list of time ranges where this sentiment appeared.
sentiment <- insights$videos$insights$sentiments[[1]]
sentiment[,1:3]
## id averageScore sentimentType
## 1 0 0.5000 Neutral
## 2 1 0.9522 Positive
## 3 2 0.1522 Negative
sentiment$instances
## [[1]]
## adjustedStart adjustedEnd start end duration
## 1 0:00:00 0:00:18.94 0:00:00 0:00:18.94 0:00:18.94
## 2 0:00:20.79 0:02:12.08 0:00:20.79 0:02:12.08 0:01:51.29
## 3 0:02:20.56 0:04:23.76 0:02:20.56 0:04:23.76 0:02:03.2
## 4 0:04:32.21 0:04:41.405 0:04:32.21 0:04:41.405 0:00:09.195
##
## [[2]]
## adjustedStart adjustedEnd start end duration
## 1 0:00:18.94 0:00:20.79 0:00:18.94 0:00:20.79 0:00:01.85
## 2 0:04:23.76 0:04:32.21 0:04:23.76 0:04:32.21 0:00:08.45
##
## [[3]]
## adjustedStart adjustedEnd start end duration
## 1 0:02:12.08 0:02:20.56 0:02:12.08 0:02:20.56 0:00:08.48
sentiment$instances %>% melt() %>%
mutate(sentiment = recode(L1, `1`='Neutral', `2`='Positive', `3`='Negative'))
## adjustedStart adjustedEnd start end duration L1 sentiment
## 1 0:00:00 0:00:18.94 0:00:00 0:00:18.94 0:00:18.94 1 Neutral
## 2 0:00:20.79 0:02:12.08 0:00:20.79 0:02:12.08 0:01:51.29 1 Neutral
## 3 0:02:20.56 0:04:23.76 0:02:20.56 0:04:23.76 0:02:03.2 1 Neutral
## 4 0:04:32.21 0:04:41.405 0:04:32.21 0:04:41.405 0:00:09.195 1 Neutral
## 5 0:00:18.94 0:00:20.79 0:00:18.94 0:00:20.79 0:00:01.85 2 Positive
## 6 0:04:23.76 0:04:32.21 0:04:23.76 0:04:32.21 0:00:08.45 2 Positive
## 7 0:02:12.08 0:02:20.56 0:02:12.08 0:02:20.56 0:00:08.48 3 Negative7.3.1.3 Emotion
Video Indexer also identifies emotions based on speech and audio cues. The identified emotion could be: joy, sadness, anger, or fear.
Practice. Get the emotion scores