Chapter 4 String and text data
Although we typically work with quantitative numerical data, the qualitative text data can be even more common. For example, the tweets on Twitter, responses to open-end questions, and diaries all include text information. In this class, we will learn how to process text data in R.
For demonstration, we will analyze the tweets from President Donald Trump. All the tweets from Donald Trump can be downloaded from the website: http://www.trumptwitterarchive.com/. For example, for the tweets in 2019, the data are in http://trumptwitterarchive.com/data/realdonaldtrump/2019.json. Changing 2019 to other years can get more tweets.
The content of the file 2019.json can be viewed in any text editor. Clearly, the data are not formatted as we typically see. But a closer look at the information will reveal it is well-organized. For example, a typical section of the data looks like
{“source”: “Twitter for iPhone”, “id_str”: “1085519375224983552”, “text”: “It is becoming more and more obvious that the Radical Democrats are a Party of open borders and crime. They want nothing to do with the major Humanitarian Crisis on our Southern Border. #2020!”, “created_at”: “Wed Jan 16 12:49:21 +0000 2019”, “retweet_count”: 22738, “in_reply_to_user_id_str”: null, “favorite_count”: 88796, “is_retweet”: false}
- Most values seem to be quoted using
" ". - The values are separated by
:or,. - A comma seems to separate a pair of values - the former is the name and the latter is its value.
- The information in within each pair of
{}has the same structure.
The way for formatting information is actually very widely used. It is called https://en.wikipedia.org/wiki/JSON (JavaScript Object Notation), a lightweight data-interchange data format. It is easy for humans to read and write and it is also easy for machines to parse and generate. The format is particularly useful for unformatted data such as the twitter text information. Particularly, this format is very similar to the list data format in R.
The data format can be parsed by R easily through the library https://cran.r-project.org/package=jsonlite. For example, to read and parse the data, we can directly use the function fromJSON from the R package jsonlite.
library(jsonlite)
trump <- fromJSON('http://trumptwitterarchive.com/data/realdonaldtrump/2019.json')
str(trump)
## 'data.frame': 1118 obs. of 8 variables:
## $ source : chr "Twitter for iPhone" "Twitter for iPhone" "Twitter for iPhone" "Twitter for iPhone" ...
## $ id_str : chr "1115295440558280704" "1115228307426095105" "1115225213426442240" "1115225104122818561" ...
## $ text : chr "The Democrats will never be satisfied, no matter what they get, how much they get, or how many pages they get. "| __truncated__ "Uganda must find the kidnappers of the American Tourist and guide before people will feel safe in going there. "| __truncated__ "RT @cspan: Rep. @Jim_Jordan on President Trump's tax returns: \"There's no law that says they have to be public"| __truncated__ "RT @Jim_Jordan: Dems want President’s tax returns for purely political purposes!\n\nFrightening, but shouldn’t "| __truncated__ ...
## $ created_at : chr "Mon Apr 08 16:48:48 +0000 2019" "Mon Apr 08 12:22:03 +0000 2019" "Mon Apr 08 12:09:45 +0000 2019" "Mon Apr 08 12:09:19 +0000 2019" ...
## $ retweet_count : int 13354 13565 6648 19161 17008 12289 15958 21908 18471 17412 ...
## $ in_reply_to_user_id_str: chr NA NA NA NA ...
## $ favorite_count : int 59065 63343 0 0 0 48292 60444 94491 74948 80825 ...
## $ is_retweet : logi FALSE FALSE TRUE TRUE TRUE FALSE ...Note fromJSON saves the data into a data frame for this particular example. We can easily see that from the beginning of 2019 to 2019-04-08, President Trump sent a total of 1118 tweets. The latest tweet is
trump[1, 'text']
## [1] "The Democrats will never be satisfied, no matter what they get, how much they get, or how many pages they get. It will never end, but that’s the way life goes!"4.1 Basic format of strings
Different from numerical values, strings often include letters, words, and punctuations. Even there are only numbers in a string, they may not have “numerical meanings.” To create a string, we need to use single or double quotation marks to close them. For example,
tweet1 <- "MAKE AMERICA GREAT AGAIN!"
tweet1
## [1] "MAKE AMERICA GREAT AGAIN!"
tweet2 <- 'Congratulations @ClemsonFB! https://t.co/w8viax0OWY'
tweet2
## [1] "Congratulations @ClemsonFB! https://t.co/w8viax0OWY"4.1.1 Special characters
- Quotation marks can be used in strings. Note that a single quote can only be used within a double quote or the other way around.
"I'm a student"
## [1] "I'm a student"
'He says "it is ok!"'
## [1] "He says \"it is ok!\""It is generally a good idea to “escape” the quotation marks using \.
"I'm a student. He says \"it is ok\"!"
## [1] "I'm a student. He says \"it is ok\"!"- The character
\.
The backslash \ is used as a special character to escape other characters. If it is needed in a string, one needs to use two of them \\. For example,
test <- "To show \\ , we need to use two of them."
cat(test)
## To show \ , we need to use two of them.- Special characters for changing lines and tab.
test <- "This is the first line. \nThis the \t second line with a tab."
cat(test)
## This is the first line.
## This the second line with a tab.\ufor escaping special characters in Unicode other than alphabetical letters. https://unicode-table.com/en/
cat("\u03BC \u03A3 \u03B1 \u03B2")
## µ S a ß4.2 Basic string operations
- String vector
(tweet <- c(tweet1, tweet2))
## [1] "MAKE AMERICA GREAT AGAIN!"
## [2] "Congratulations @ClemsonFB! https://t.co/w8viax0OWY"- Change the lower/upper case
tolower(tweet)
## [1] "make america great again!"
## [2] "congratulations @clemsonfb! https://t.co/w8viax0owy"
toupper(tweet)
## [1] "MAKE AMERICA GREAT AGAIN!"
## [2] "CONGRATULATIONS @CLEMSONFB! HTTPS://T.CO/W8VIAX0OWY"- Length of a string
nchar(tweet1)
## [1] 25
str_length(tweet) # function of stringr
## [1] 25 51- Split strings. (1)
patterntells how to split a string. (2) the output is a list.
str_split(tweet, pattern = " ")
## [[1]]
## [1] "MAKE" "AMERICA" "GREAT" "AGAIN!"
##
## [[2]]
## [1] "Congratulations" "@ClemsonFB!"
## [3] "https://t.co/w8viax0OWY"- Combine strings
tweet.words <- str_split(tweet, pattern = " ")
str_c(unlist(tweet.words), collapse=" ")
## [1] "MAKE AMERICA GREAT AGAIN! Congratulations @ClemsonFB! https://t.co/w8viax0OWY"- Subset strings
str_sub(tweet, start=1, end=3)
## [1] "MAK" "Con"
tweet
## [1] "MAKE AMERICA GREAT AGAIN!"
## [2] "Congratulations @ClemsonFB! https://t.co/w8viax0OWY"
str_sub(tweet, start=-3, end=-1)
## [1] "IN!" "OWY"- Compare strings
tweet1 == tweet2
## [1] FALSE
tweet == tweet1
## [1] TRUE FALSE
identical(tweet1, tweet2)
## [1] FALSE- Whether a string vector includes a string
tweet1 %in% tweet
## [1] TRUE- Whether a string includes another string
grepl(pattern = "test", "test this")
## [1] TRUE
grepl(pattern = "es", "test this")
## [1] TRUE
grepl(pattern = "test1", "test this")
## [1] FALSE
grep(pattern = "test", "test this")
## [1] 1
grep(pattern = "GREAT", tweet)
## [1] 1
grep(pattern = "GREAT", tweet, value = TRUE)
## [1] "MAKE AMERICA GREAT AGAIN!"grep stands for globally search a regular expression and print. grep returns the index and grepl returns TRUE or FALSE.
4.2.1 Basic analysis of Trump tweets
- Where the tweets were sent
table(trump$source)
##
## Twitter for iPad Twitter for iPhone Twitter Media Studio
## 1 1103 13
## Twitter Web Client
## 1- The length of each tweet
str_length(trump$text)
## [1] 159 152 140 140 140 122 226 204 284 203 127 139 143 142 286 241 284 284
## [19] 71 245 299 211 280 137 280 139 280 280 54 85 91 120 140 62 163 61
## [37] 134 140 140 63 140 73 98 61 283 279 97 74 211 41 90 264 280 280
## [55] 129 265 111 81 96 47 41 273 161 280 216 56 198 174 279 288 124 272
## [73] 268 23 271 182 277 102 280 279 292 260 288 278 282 291 284 150 170 242
## [91] 248 139 140 163 270 259 266 264 278 282 278 215 154 284 288 274 283 280
## [109] 279 284 80 152 54 73 122 130 99 281 208 23 23 119 234 130 109 277
## [127] 283 291 23 23 140 179 118 184 23 137 276 23 23 279 126 195 54 59
## [145] 199 200 140 271 139 75 139 125 50 139 140 107 258 23 23 52 102 46
## [163] 72 250 246 81 25 31 172 215 211 217 153 23 23 272 23 46 140 140
## [181] 140 140 140 227 213 213 105 192 23 72 23 141 48 270 261 286 233 45
## [199] 288 284 140 91 143 23 65 180 82 38 245 23 23 138 288 23 227 261
## [217] 23 271 186 158 186 55 278 280 25 210 270 140 110 116 140 140 67 110
## [235] 53 140 129 129 138 107 140 140 253 217 278 23 266 23 288 280 51 282
## [253] 283 223 280 282 140 72 144 144 144 227 173 250 278 55 139 140 140 176
## [271] 23 110 23 219 23 23 295 23 147 176 273 51 284 288 284 226 269 65
## [289] 23 266 5 131 118 162 204 46 280 139 124 278 280 140 118 279 114 23
## [307] 258 134 144 140 140 136 196 201 197 19 25 279 205 268 120 131 131 140
## [325] 140 119 140 139 139 51 140 138 144 140 140 140 140 140 192 140 266 280
## [343] 275 280 280 140 140 54 292 140 140 140 140 139 140 124 139 105 140 214
## [361] 140 127 287 140 140 155 140 140 139 48 51 140 49 273 280 281 140 139
## [379] 140 219 23 165 140 62 109 69 107 120 75 140 140 140 140 140 52 135
## [397] 139 140 140 144 140 139 167 199 279 42 185 95 119 152 281 24 104 37
## [415] 210 111 267 111 188 251 256 92 217 288 140 111 139 140 276 139 48 140
## [433] 88 192 181 141 280 242 80 24 254 117 284 105 231 251 250 144 205 280
## [451] 48 139 166 283 279 279 271 59 230 81 118 105 140 139 283 90 245 270
## [469] 257 284 280 288 23 87 135 277 49 63 140 140 140 140 140 84 127 134
## [487] 187 264 271 272 271 280 269 279 208 234 23 23 70 71 150 140 140 161
## [505] 116 39 39 285 239 282 274 140 140 140 172 274 126 181 204 120 101 178
## [523] 279 282 263 148 211 126 277 229 280 140 139 107 280 140 275 283 280 134
## [541] 271 201 277 279 279 277 279 140 140 140 106 139 140 72 140 157 136 128
## [559] 279 34 82 211 159 140 52 60 277 110 288 231 130 65 274 279 119 190
## [577] 279 75 279 232 274 56 101 144 23 276 151 173 276 172 276 151 276 99
## [595] 140 72 37 32 284 282 268 130 217 144 89 110 33 278 277 218 84 152
## [613] 140 140 190 279 23 23 56 261 152 270 234 117 110 140 108 277 279 44
## [631] 267 18 23 23 134 23 136 276 140 159 302 59 12 254 284 257 112 23
## [649] 23 140 274 127 107 140 248 140 140 115 44 116 216 90 126 109 284 140
## [667] 195 165 213 23 123 102 105 75 64 69 88 136 89 274 280 257 292 280
## [685] 272 264 140 84 270 279 276 265 132 140 140 140 139 114 40 140 277 275
## [703] 284 283 287 186 246 48 284 284 221 274 278 77 297 196 54 68 191 278
## [721] 280 23 50 50 29 57 277 270 228 251 275 276 292 110 269 273 121 228
## [739] 127 131 96 41 95 274 280 49 273 287 132 216 300 23 277 277 221 274
## [757] 91 280 278 280 279 181 277 89 275 296 94 216 39 273 280 92 168 280
## [775] 280 284 267 113 252 278 277 235 264 138 278 287 281 280 59 69 140 140
## [793] 115 140 276 267 248 11 274 280 185 178 59 284 275 250 283 287 291 267
## [811] 23 164 279 90 238 118 280 288 283 132 284 187 232 280 103 108 263 35
## [829] 167 140 278 282 283 288 286 86 256 275 144 284 272 74 280 140 282 252
## [847] 279 279 174 138 140 123 247 264 109 191 140 156 274 118 140 89 37 136
## [865] 140 48 144 140 140 140 140 96 144 140 140 140 102 140 139 144 140 139
## [883] 52 140 23 275 40 241 201 274 283 280 288 263 283 23 48 253 284 283
## [901] 277 122 43 140 140 261 140 119 140 23 140 140 139 124 144 152 84 94
## [919] 59 102 171 23 14 25 284 278 70 68 282 188 208 269 226 140 140 144
## [937] 116 89 192 278 248 51 69 140 140 144 139 140 140 107 140 140 138 248
## [955] 248 270 185 234 278 154 238 284 110 122 137 277 23 280 61 158 119 86
## [973] 140 140 140 140 140 278 274 284 164 230 229 280 278 280 199 275 201 145
## [991] 109 148 276 23 207 273 280 140 283 198
## [ reached getOption("max.print") -- omitted 118 entries ]
hist(str_length(trump$text))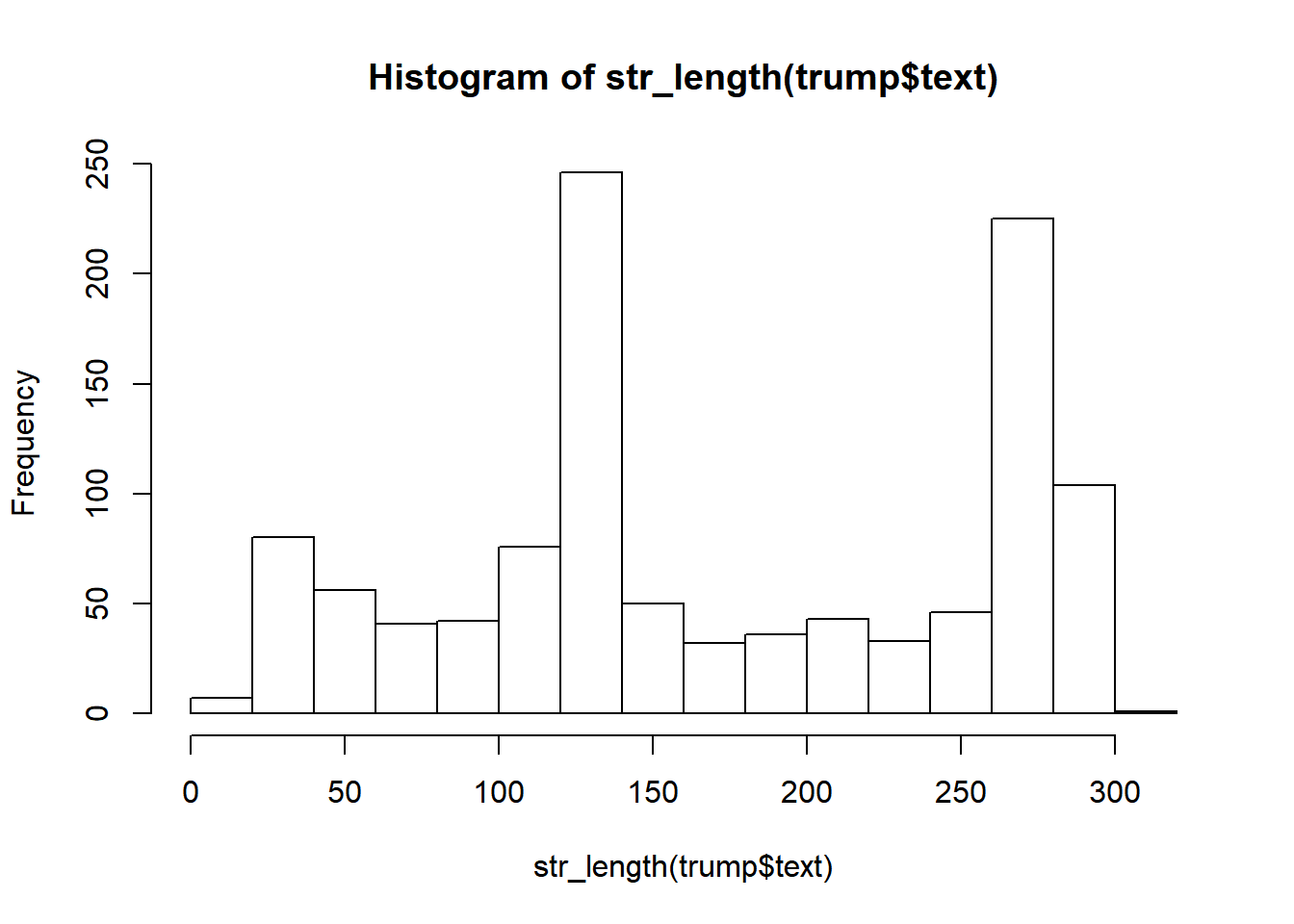
plot(str_length(trump$text), type='h') - Number of words in the tweets
- Number of words in the tweets
trump.split <- str_split(trump$text, pattern = " ")
lengths(trump.split)
## [1] 31 26 22 18 13 21 38 37 44 32 21 25 27 24 49 40 45 50 4 41 48 34 54 19
## [25] 54 23 47 50 7 11 13 17 20 10 28 7 23 23 21 7 17 15 13 6 53 47 11 12
## [49] 34 4 17 42 51 48 18 47 16 10 15 4 4 48 29 46 37 10 27 28 46 49 16 35
## [73] 47 1 43 31 46 12 45 46 49 48 45 47 45 46 44 23 29 38 41 24 20 27 42 43
## [97] 45 41 45 53 53 33 23 51 53 49 46 52 45 47 11 26 6 6 16 18 16 46 30 1
## [121] 1 21 43 20 19 49 51 48 1 1 18 27 18 29 1 17 45 1 1 48 15 32 5 9
## [145] 31 32 23 48 21 8 19 18 6 20 27 13 34 1 1 8 13 6 9 36 42 11 4 6
## [169] 25 34 40 39 26 1 1 47 1 10 20 23 21 19 22 32 33 35 15 32 1 13 1 22
## [193] 5 49 45 54 39 5 54 50 24 12 27 1 8 33 15 4 46 1 1 16 49 1 35 42
## [217] 1 46 34 30 34 9 54 52 4 36 54 23 15 16 17 19 8 12 4 27 14 15 18 13
## [241] 21 24 44 32 48 1 48 1 51 47 6 50 51 38 47 46 23 10 21 23 26 42 30 44
## [265] 43 5 23 25 25 26 1 13 1 36 1 1 45 1 28 29 48 8 47 48 48 32 48 6
## [289] 1 42 1 18 20 28 30 5 48 22 19 46 47 19 18 42 21 1 44 23 17 17 25 20
## [313] 32 33 32 3 4 46 35 43 20 20 20 21 14 19 23 24 23 7 21 21 26 22 26 21
## [337] 18 21 32 24 48 48 46 45 49 18 18 9 52 23 17 26 14 21 24 18 20 15 23 36
## [361] 24 23 43 21 24 27 18 19 19 6 6 20 5 45 48 47 23 23 23 38 1 34 22 7
## [385] 14 5 11 19 7 19 17 16 19 20 6 24 21 19 17 22 22 16 31 32 50 8 22 17
## [409] 21 30 51 2 20 5 36 14 49 20 32 45 41 10 32 45 19 17 27 19 46 19 3 18
## [433] 9 35 33 22 45 40 12 2 46 20 49 15 37 38 38 24 37 44 3 24 25 53 53 51
## [457] 51 8 41 11 15 14 22 21 49 17 41 50 44 49 47 53 1 14 25 48 3 14 22 22
## [481] 24 19 20 14 17 26 30 46 45 46 45 49 42 48 38 37 1 1 12 11 22 19 22 21
## [505] 19 3 3 48 42 49 49 26 19 25 29 48 23 33 31 22 18 29 46 40 47 27 37 23
## [529] 50 41 46 24 24 20 49 19 46 47 41 24 48 33 44 46 49 46 49 22 22 19 12 21
## [553] 19 11 22 24 20 18 55 6 14 34 26 22 6 9 44 9 37 40 21 8 45 49 21 29
## [577] 45 15 51 34 50 11 15 19 1 49 27 27 49 27 49 29 41 16 21 10 4 2 47 44
## [601] 48 23 33 23 13 19 4 52 49 33 10 20 23 25 29 46 1 1 11 44 27 46 39 13
## [625] 12 19 13 55 51 3 46 3 1 1 22 1 17 43 23 30 44 10 2 47 51 43 13 1
## [649] 1 27 45 23 16 26 46 23 21 10 5 20 36 13 16 12 47 20 31 28 30 1 22 19
## [673] 20 13 11 7 16 23 11 44 44 40 49 50 49 49 24 14 41 49 47 47 20 23 22 20
## [697] 19 14 3 22 48 47 49 51 52 36 36 5 50 46 37 39 44 16 46 24 5 10 32 48
## [721] 45 1 3 3 1 6 40 51 41 42 45 45 49 20 45 45 15 30 23 22 13 4 19 49
## [745] 50 6 48 51 23 39 51 1 47 54 36 47 15 46 48 47 50 31 47 18 50 57 14 31
## [769] 6 47 48 12 27 46 44 44 39 19 48 48 46 36 47 21 49 49 47 47 8 2 27 20
## [793] 21 19 47 44 38 2 46 47 31 32 8 49 46 48 49 49 49 54 1 27 51 16 41 23
## [817] 48 51 48 22 51 33 40 54 14 15 38 7 31 26 51 41 45 47 52 17 50 47 23 43
## [841] 48 10 54 24 43 40 51 50 31 23 28 16 43 48 17 31 21 27 52 16 23 13 3 15
## [865] 14 6 20 18 22 27 22 12 21 20 22 25 13 20 20 20 23 23 5 16 1 50 4 40
## [889] 38 50 51 53 56 48 48 1 11 51 46 55 48 24 9 22 22 43 23 22 23 1 14 20
## [913] 25 18 23 27 10 13 9 16 27 1 2 4 49 46 13 10 48 32 36 43 39 22 27 22
## [937] 23 16 34 49 44 3 13 17 27 19 21 21 24 13 23 21 19 44 42 50 29 44 51 32
## [961] 42 48 12 15 16 49 1 46 10 26 22 15 21 17 20 18 22 49 47 43 29 37 37 47
## [985] 50 43 35 47 41 25 19 27 49 1 40 49 52 22 46 35
## [ reached getOption("max.print") -- omitted 118 entries ]
hist(lengths(trump.split))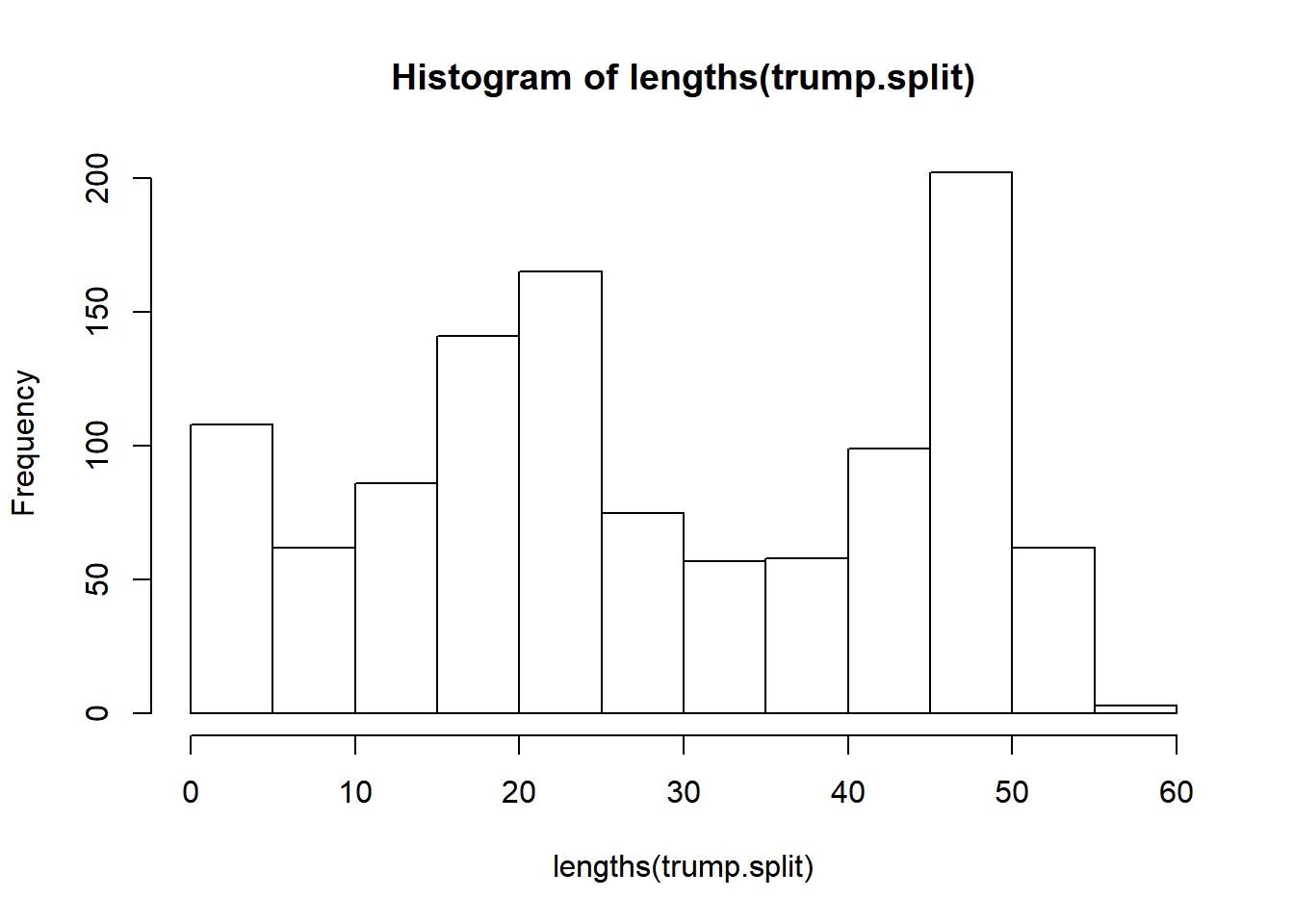
hist(lengths(trump.split[!trump$is_retweet]))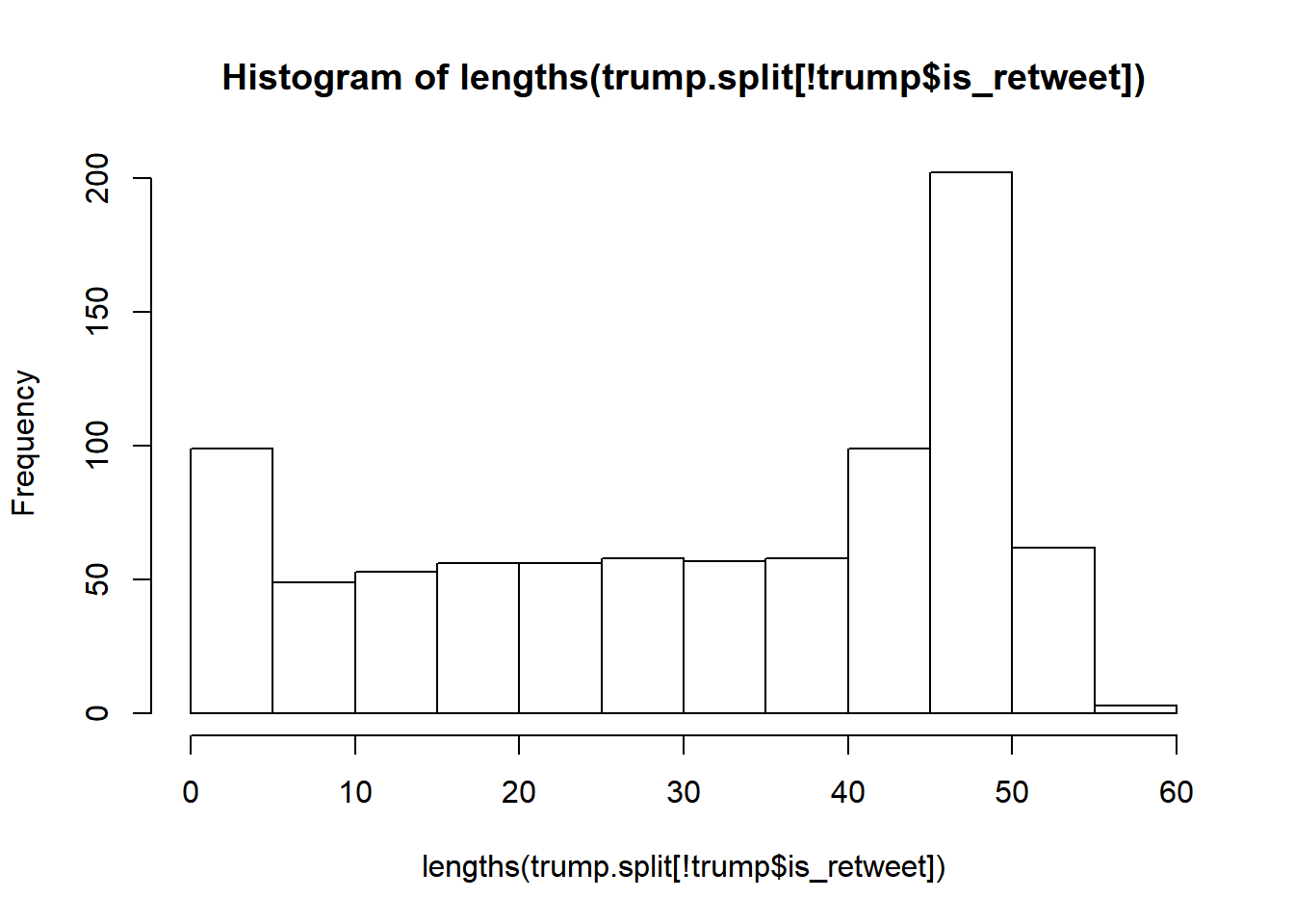
- Most frequently used words
trump.split <- unlist(str_split(trump$text, pattern = " "))
head(sort(table(trump.split), decreasing = TRUE))
## trump.split
## the to and of a in
## 1378 763 682 631 486 418
word.freq <- sort(table((trump.split)), decreasing = TRUE)
barplot(word.freq[1:50], las=2)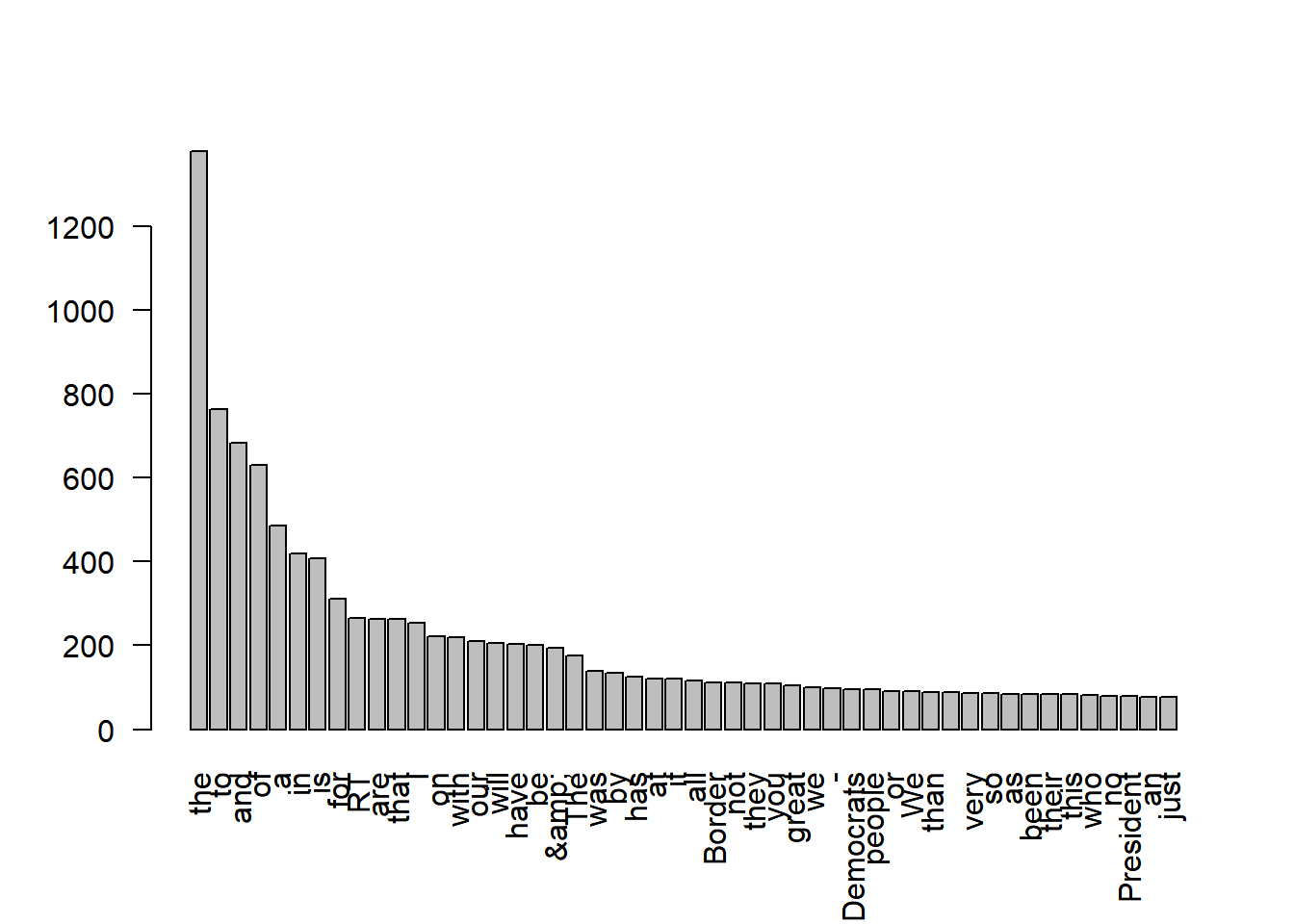
- Word length of tweets
summary(str_length(trump.split))
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.000 3.000 4.000 5.142 7.000 45.000
hist(str_length(trump.split))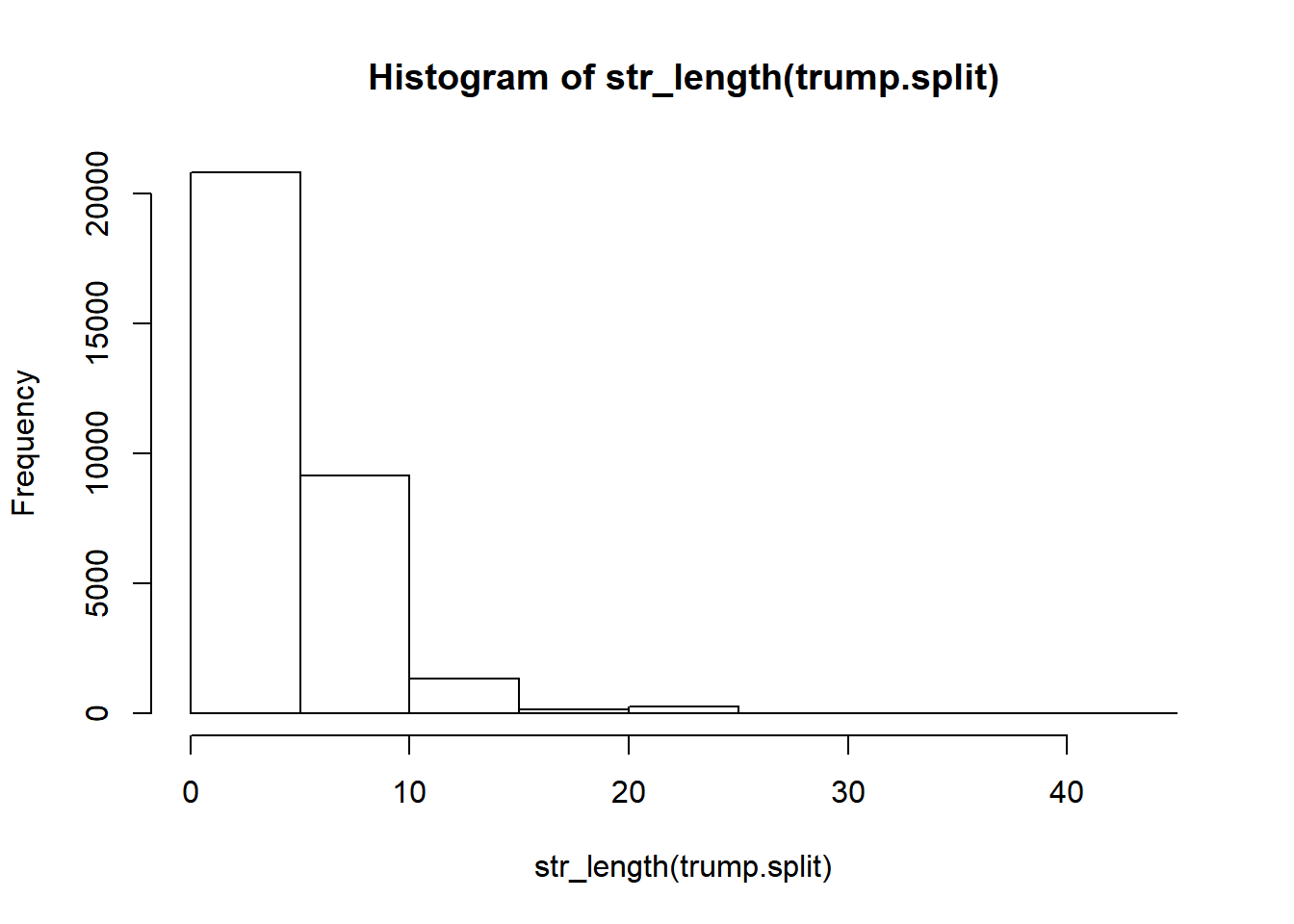
4.3 Search strings and texts
Search is a process of matching - to match a pattern in the target. Complex search is usually conducted through regular expression. A regular expression, regex or regexp (sometimes called a rational expression) is a sequence of characters that define a search pattern. Usually, this pattern is used by string searching algorithms for “find” or “find and replace” operations on strings, or for input validation. It is a technique that developed in theoretical computer science and formal language theory.
4.3.1 Basics of regular expression
To learn the basics of regular expression, we use the website https://regex101.com/. As an example, let’s focus on the text below.
{"source": "Twitter for iPhone", "id_str": "1085519375224983552", "text": "It is becoming more and more obvious that the Radical Democrats are a Party of open borders and crime. They want nothing to do with the major Humanitarian Crisis on our Southern Border. #2020!", "created_at": "Wed Jan 16 12:49:21 +0000 2019", "retweet_count": 22738, "in_reply_to_user_id_str": null, "favorite_count": 88796, "is_retweet": false}- Search regular characters or words. For example, try out “is” and “they”.
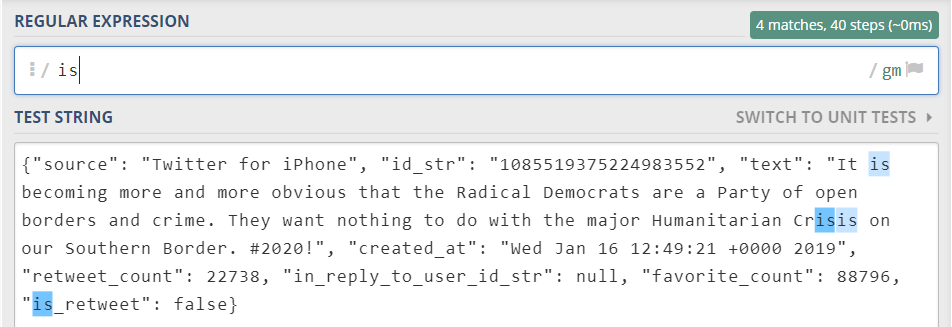
When use R studio together with the package htmlwidgets, we can use str_view_all() function from the package stringr to view the search results.
tweet <- '{"source": "Twitter for iPhone", "id_str": "1085519375224983552", "text": "It is becoming more and more obvious that the Radical Democrats are a Party of open borders and crime. They want nothing to do with the major Humanitarian Crisis on our Southern Border. #2020!", "created_at": "Wed Jan 16 12:49:21 +0000 2019", "retweet_count": 22738, "in_reply_to_user_id_str": null, "favorite_count": 88796, "is_retweet": false}'
str_view_all(tweet, "is")str_view_all(tweet, "they")- Match whole words only.
\bsets the boundary of a search that allows the search of whole words. Try out\bis\b. Also try\Bis\B[only non-whole words].
str_view_all(tweet, "\\bis\\b")
str_view_all(tweet, "\\Bis\\B")- Ignore letter case.
[tT]hey. Use[]to specify multiple letters to match(?i). Completely ignore case.
str_view_all(tweet, "[tT]hey")
str_view_all(tweet, "(?i)thEy")- Search a simple pattern. For example, we want to search 4 characters with “mo” in the middle so that “xmox”. To do it, we use the period “.” which matches anything except for line terminators. For example, try
.mo..
str_view_all(tweet, ".mo.")
str_view_all(tweet, "(?i).cr.")- Search period “.”. To do it, we need to escape it using
\.or use[.].
str_view_all(tweet, "\\.")- Search common special characters.
- white space/tab/newline
\s, non-white space\S. - any digit number
\d, any non-digit number\D - any word character
\w, any non-word character\W
- white space/tab/newline
str_view_all(tweet, "\\s")str_view_all(tweet, "\\S")
str_view_all(tweet, "\\d")str_view_all(tweet, "\\D")
str_view_all(tweet, "\\w")str_view_all(tweet, "\\W")- Use of ?, *, and +. Try out
en?,en*,en+.- a?: zero or one of a
- a*: zero or more of a
- a+: one or more of a.
str_view_all(tweet, "en?")
str_view_all(tweet, "en*")
str_view_all(tweet, "en+")Match repitions. a{2} match 2 a’s; a{2, } match 2 or more a’s; a{,2} match at most 2 times; a{2,4} match 2 to 4 a’s.
Use of
^and$. start of string^, end of a string$
str_view_all(tweet, "^")
str_view_all(tweet, "$")- Match either character (a|b). Try
r(e|a). or Use [ab] Tryr[ea].
str_view_all(tweet, "r(e|a)")
str_view_all(tweet, "r[ea]")- Not match something [^ab]: anything except for a and b.
str_view_all(tweet, "[^ab]")4.3.2 Regular expression in action
- Find tweets with specific words
head(str_detect(trump$text, "(?i)great"))
## [1] FALSE FALSE FALSE FALSE FALSE FALSE
mean(str_detect(trump$text, "(?i)great"))
## [1] 0.1690519
mean(str_detect(trump$text, "(?i)wall"))
## [1] 0.08855098- Find a link
str_detect(trump$text, "https?://t.co")
mean(str_detect(trump$text, "https?://t.co"))
grep("https?://t.co", trump$text, value=TRUE)
grep("https?://t.co", trump$text)
str_detect(trump$text, "\\bRT\\b")
str_detect(trump$text, "@[a-zA-Z]+")- Count the words with all capital letters
word.count <- str_count(trump$text, "[A-Z]{2,}")
word.count
## [1] 0 0 1 1 3 0 0 1 1 1 0 5 1 0 0 1 0 0 1 0 7 4 1 2
## [25] 1 3 1 0 1 1 5 3 4 0 0 6 3 2 1 0 1 1 2 1 2 8 1 0
## [49] 0 3 0 2 0 1 1 1 1 0 0 0 4 0 0 0 2 10 5 0 0 0 2 3
## [73] 0 2 3 0 0 2 7 0 1 0 2 0 1 0 0 0 0 0 0 2 1 4 0 1
## [97] 1 0 0 1 1 0 1 2 1 0 1 0 2 9 2 0 1 6 3 7 3 0 0 1
## [121] 1 1 2 0 2 2 1 0 1 1 4 0 0 0 1 2 3 1 1 0 2 2 0 0
## [145] 0 0 4 1 3 2 1 3 0 2 1 3 1 1 2 1 5 5 1 0 0 4 4 0
## [169] 2 0 0 0 2 1 0 2 0 8 1 3 3 1 1 3 4 0 0 0 1 3 2 4
## [193] 2 2 3 2 0 0 0 0 4 1 3 1 1 1 0 0 1 0 1 1 4 1 2 1
## [217] 1 4 3 0 0 0 0 1 4 0 3 2 2 2 1 3 3 5 2 1 4 4 4 1
## [241] 2 3 1 1 1 0 2 0 0 1 1 2 2 1 2 0 2 8 1 1 4 0 0 4
## [265] 0 2 1 1 1 0 2 2 1 0 0 0 0 1 0 0 2 7 0 0 4 1 0 1
## [289] 0 4 1 4 0 2 2 0 0 0 0 0 0 2 1 1 1 1 3 0 1 1 3 1
## [313] 0 1 1 3 4 1 0 0 2 1 1 3 1 1 1 2 1 1 1 1 2 2 4 1
## [337] 1 2 2 2 0 1 0 0 0 2 2 0 0 7 5 3 4 1 3 2 1 2 1 1
## [361] 1 0 0 1 1 0 3 1 2 1 2 1 0 4 0 0 1 3 3 0 2 0 2 1
## [385] 3 2 6 2 1 1 2 1 3 3 1 0 1 2 2 1 3 1 0 0 1 0 2 0
## [409] 0 0 2 2 0 0 0 1 1 0 0 0 0 1 0 2 3 1 3 1 0 2 1 2
## [433] 2 0 0 1 5 5 4 2 0 1 2 1 0 0 0 1 0 0 1 1 0 4 3 2
## [457] 2 2 0 2 4 2 4 1 0 2 0 0 0 1 0 0 2 2 0 0 1 0 1 1
## [481] 2 4 5 1 1 0 0 0 0 0 0 0 0 0 0 5 0 2 0 1 3 1 1 1
## [505] 0 1 1 0 2 0 0 1 1 1 0 1 0 0 1 0 0 0 0 0 0 4 1 0
## [529] 0 0 0 2 1 1 0 1 0 0 0 1 2 1 1 0 0 0 3 2 2 3 3 3
## [553] 2 1 4 0 1 2 1 0 0 0 0 2 0 1 11 4 1 4 2 9 0 0 0 3
## [577] 1 4 1 1 1 0 1 1 0 1 0 0 0 0 0 0 0 0 1 1 3 2 2 5
## [601] 4 2 3 2 0 0 0 0 1 2 2 2 4 2 0 0 0 1 11 1 3 1 0 3
## [625] 2 2 1 1 1 2 0 3 1 0 0 1 2 0 1 0 4 0 0 8 1 0 3 3
## [649] 0 1 1 0 12 1 0 1 1 3 2 1 0 2 1 3 2 2 1 1 2 1 0 1
## [673] 0 0 1 1 2 4 2 0 0 0 0 0 1 0 0 0 6 0 1 0 2 1 2 1
## [697] 1 2 1 2 1 0 1 0 0 0 0 0 5 3 1 0 0 0 1 2 1 2 1 0
## [721] 0 1 2 2 1 3 0 0 0 0 3 3 0 1 0 0 1 0 2 2 1 4 1 1
## [745] 0 0 5 1 0 1 1 0 1 0 0 0 0 2 1 0 0 0 1 3 2 1 0 0
## [769] 0 0 1 0 0 0 0 1 0 0 0 0 0 2 0 0 3 7 5 4 7 4 2 7
## [793] 2 2 2 1 1 2 0 1 0 0 6 0 2 0 0 1 1 0 2 3 1 0 0 7
## [817] 0 0 1 1 2 0 1 0 2 9 2 5 5 0 0 2 0 4 0 0 0 0 2 3
## [841] 0 0 0 1 0 0 0 0 0 3 6 1 2 2 0 0 2 0 10 1 3 1 1 3
## [865] 5 0 1 1 1 1 2 3 4 1 2 6 3 1 1 1 2 2 2 3 1 0 1 0
## [889] 0 0 0 1 0 0 3 1 0 1 0 0 0 0 4 1 1 0 1 2 2 0 1 2
## [913] 1 4 2 1 4 2 1 1 0 0 2 4 0 0 0 0 0 0 0 0 0 1 1 1
## [937] 3 0 0 0 0 2 0 3 1 2 3 3 1 4 4 2 2 0 0 0 0 0 2 1
## [961] 2 1 3 3 2 3 0 1 0 0 0 0 2 2 2 2 2 0 1 1 0 2 0 0
## [985] 3 1 4 0 0 0 0 1 1 1 0 0 1 0 0 0
## [ reached getOption("max.print") -- omitted 118 entries ]4.4 Replace strings
Sometimes, we want to replace the matched pattern. For example, take a close look at the tweets. We find some special characters such as &, which is the html encoding of &. In addition, we see that \n is used to change lines. Suppose here we want to replace & with & and \n with empty.
replace.vec <- c("&" = "&", "\\n"="")
tweet.rep <- str_replace_all(trump$text, replace.vec)The stri_replace_all_regex() function from the R package stringi provides more ways for replacement.
library(stringi)
tweet.rep <- stri_replace_all_regex(trump$text, c("&", "\\n"), c("&", ""),
vectorize_all = FALSE)
tweet.repReplace punctation and numbers
tweet.rep <- stri_replace_all_regex(tweet, "[:punct:]|[:digit:]", "", vectorize_all = FALSE)
tweet.rep
## [1] "source Twitter for iPhone idstr text It is becoming more and more obvious that the Radical Democrats are a Party of open borders and crime They want nothing to do with the major Humanitarian Crisis on our Southern Border createdat Wed Jan + retweetcount inreplytouseridstr null favoritecount isretweet false"4.4.1 Example
As another example, we look at a messier data. The file evaluation.csv includes teaching evaluation data from 20 students.
cif <- read.csv('data/evaluation.csv', stringsAsFactors = FALSE)
str(cif)
## 'data.frame': 20 obs. of 2 variables:
## $ id : int 1 2 3 4 5 6 7 8 9 10 ...
## $ comment: chr "Mr . Len is so cool . he will teach you all the things you want to know about photography . he is the best out "| __truncated__ "easy class, but take notes b/c you have a 11 page mid-term . The teacher remembers your name ." "ey Mr Len this is Karl! aight folks this class is funn as hell! i recommend you take it . take it now! go on cl"| __truncated__ "len's absolutely awesome . he's willing to take time out of his day to help you whenever you need it, and he's "| __truncated__ ...4.4.1.1 Remove identification information
The comments mentioned “Len” and “Cook”. To anonymize data, we first should remove such information.
cif$comment <- stri_replace_all_regex(cif$comment, c("(?i)len", "(?i)cook"), c("", ""),
vectorize_all = FALSE)
cif$comment[1:5]
## [1] "Mr . is so cool . he will teach you all the things you want to know about photography . he is the best out there IMO . he also has a studio which has all the equipments you need . . .TAKE HIS CLASS @ chabot college . . ."
## [2] "easy class, but take notes b/c you have a 11 page mid-term . The teacher remembers your name ."
## [3] "ey Mr this is Karl! aight folks this class is funn as hell! i recommend you take it . take it now! go on class web and look for Photo50 with Mr . "
## [4] "'s absolutely awesome . he's willing to take time out of his day to help you whenever you need it, and he's extremely enthusiastic about the subject, which really helps make the class interesting . he's quick witted, smart and he makes it easy to pass the class as long as you take the time to do the work well and you improve ."
## [5] "Mr . Rocks!!! He is a very understanding teacher and is committed to helping do your best with his assignments . He goes out of his way to give you step by step hands on instructions . He is great for beginers ."4.4.1.2 Replace contraction
Replace contraction can help future analysis. At least two things need consideration here.
- Whole words: note the use of double backslash \\.
- Ignore cases
cif$comment <- stri_replace_all_regex(cif$comment, c("(?i)\\bHe's\\b", "(?i)\\bI'm\\b", "(?i)\\bdidn't\\b", "(?i)\\bwasn't\\b"), c("he is", "I am", "did not", "was not"),
vectorize_all = FALSE)
cif$comment[1:5]
## [1] "Mr . is so cool . he will teach you all the things you want to know about photography . he is the best out there IMO . he also has a studio which has all the equipments you need . . .TAKE HIS CLASS @ chabot college . . ."
## [2] "easy class, but take notes b/c you have a 11 page mid-term . The teacher remembers your name ."
## [3] "ey Mr this is Karl! aight folks this class is funn as hell! i recommend you take it . take it now! go on class web and look for Photo50 with Mr . "
## [4] "'s absolutely awesome . he is willing to take time out of his day to help you whenever you need it, and he is extremely enthusiastic about the subject, which really helps make the class interesting . he is quick witted, smart and he makes it easy to pass the class as long as you take the time to do the work well and you improve ."
## [5] "Mr . Rocks!!! He is a very understanding teacher and is committed to helping do your best with his assignments . He goes out of his way to give you step by step hands on instructions . He is great for beginers ."4.4.1.3 Correct the spelling error
The same method for replacing contractions can be used.
4.4.1.4 Remove special patterns
Some patterns such as 53B and Photo50 do not provide much useful information. We can remove those terms. They are typically a combination of numbers and letters.
cif$comment <- stri_replace_all_regex(cif$comment, "[\\w]+[\\d]+[\\w]+", "",
vectorize_all = FALSE)
cif$comment[1:5]
## [1] "Mr . is so cool . he will teach you all the things you want to know about photography . he is the best out there IMO . he also has a studio which has all the equipments you need . . .TAKE HIS CLASS @ chabot college . . ."
## [2] "easy class, but take notes b/c you have a 11 page mid-term . The teacher remembers your name ."
## [3] "ey Mr this is Karl! aight folks this class is funn as hell! i recommend you take it . take it now! go on class web and look for with Mr . "
## [4] "'s absolutely awesome . he is willing to take time out of his day to help you whenever you need it, and he is extremely enthusiastic about the subject, which really helps make the class interesting . he is quick witted, smart and he makes it easy to pass the class as long as you take the time to do the work well and you improve ."
## [5] "Mr . Rocks!!! He is a very understanding teacher and is committed to helping do your best with his assignments . He goes out of his way to give you step by step hands on instructions . He is great for beginers ."4.4.2 replace space+dot with a single dot
cif$comment <- stri_replace_all_regex(cif$comment, "\\s+[.]", ".",
vectorize_all = FALSE)
cif$comment[1:5]
## [1] "Mr. is so cool. he will teach you all the things you want to know about photography. he is the best out there IMO. he also has a studio which has all the equipments you need...TAKE HIS CLASS @ chabot college..."
## [2] "easy class, but take notes b/c you have a 11 page mid-term. The teacher remembers your name."
## [3] "ey Mr this is Karl! aight folks this class is funn as hell! i recommend you take it. take it now! go on class web and look for with Mr. "
## [4] "'s absolutely awesome. he is willing to take time out of his day to help you whenever you need it, and he is extremely enthusiastic about the subject, which really helps make the class interesting. he is quick witted, smart and he makes it easy to pass the class as long as you take the time to do the work well and you improve."
## [5] "Mr. Rocks!!! He is a very understanding teacher and is committed to helping do your best with his assignments. He goes out of his way to give you step by step hands on instructions. He is great for beginers."4.4.3 remove punctuations
cif$comment <- stri_replace_all_regex(cif$comment, "[:punct:]", "",
vectorize_all = FALSE)
cif$comment[1:5]
## [1] "Mr is so cool he will teach you all the things you want to know about photography he is the best out there IMO he also has a studio which has all the equipments you needTAKE HIS CLASS chabot college"
## [2] "easy class but take notes bc you have a 11 page midterm The teacher remembers your name"
## [3] "ey Mr this is Karl aight folks this class is funn as hell i recommend you take it take it now go on class web and look for with Mr "
## [4] "s absolutely awesome he is willing to take time out of his day to help you whenever you need it and he is extremely enthusiastic about the subject which really helps make the class interesting he is quick witted smart and he makes it easy to pass the class as long as you take the time to do the work well and you improve"
## [5] "Mr Rocks He is a very understanding teacher and is committed to helping do your best with his assignments He goes out of his way to give you step by step hands on instructions He is great for beginers"4.5 Make sense of text data - text sentiment
A tweet or any other text may reflect the feeling, emotion, or sentiment of the writer at the time. It might be easy for the human being to sense the feeling of a tweet. But it is a totally different story for a computer to understand that. For massive data, however, it is useful to automate the procedure using computers. Text mining, which can be used to understand the sentiment of text, is a popular research area. In fact, both Google and Microsoft have developed tools to do the job.
4.5.1 Microsoft Text Analytics
To simply test the Microsoft Text Analytics, go to the website: https://azure.microsoft.com/en-us/services/cognitive-services/text-analytics/
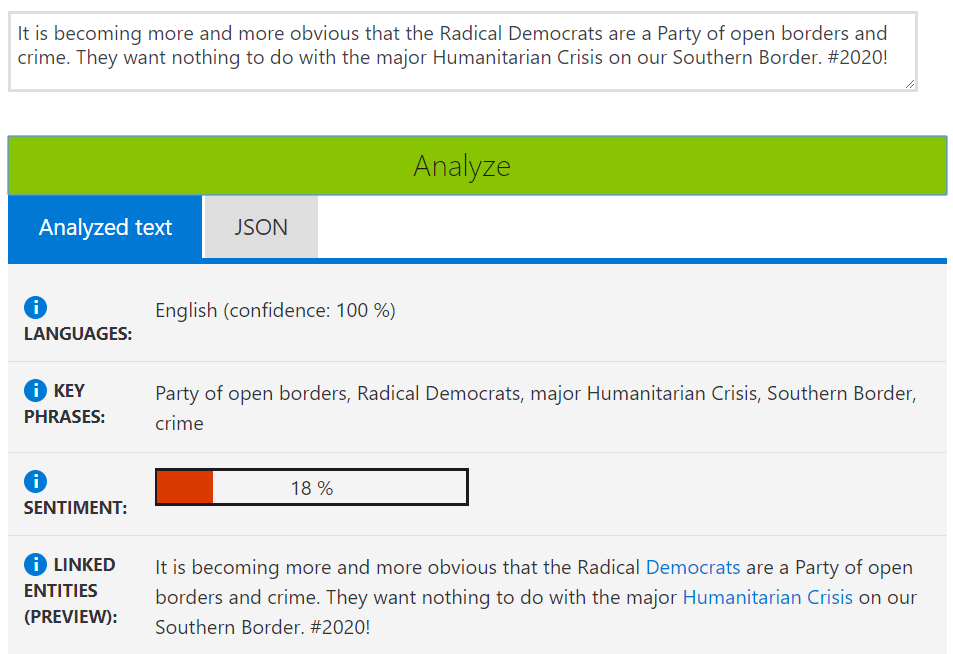
For a quick test, we analyze this tweet.
It is becoming more and more obvious that the Radical Democrats are a Party of open borders and crime. They want nothing to do with the major Humanitarian Crisis on our Southern Border. #2020!Here is the screenshot of the analysis. The output includes
- The language of the text. The detected language and a numeric score between 0 and 1. Scores close to 1 indicate more certain that the identified language is true. A total of 120 languages are supported.
- Key phrases used in the text. A list of strings denoting the key talking points in the input text.
- Sentiment of the text. A numeric score between 0 and 1. Scores close to 1 indicate positive sentiment, and scores close to 0 indicate negative sentiment.
- Linked entities. Those are well-known phrases and linked to known sources such as Wikipedia.
- JSON format output. The output is also formatted as a JSON entry.
4.5.1.1 API
Microsoft provides an API that can be used within R for text analysis. In computer programming, an application programming interface (API) provides a way to communicate among programs. To use the Text Analytics API, one needs to register with Microsoft Azure for a free account https://azure.microsoft.com/en-us/free/ai/ to get a key to use with the API.
For this class, you can temporarily use my API key - 41043e511ca44ba1ad1c3154066d7e05. The key will expire in a couple of weeks. If you plan to do research in text analysis, it is better to get your own key. And in general, you should not share your key or this key with others.
To use the API, we need to transfer data to Azure, uploading data to the server of Microsoft. Therefore, make sure you will remove any identification or sensitive information from your data.
The data requires to be in the json format like below.
{
"documents": [
{
"id": "1",
"text": "Hello world"
},
{
"id": "2",
"text": "Bonjour tout le monde"
},
{
"id": "3",
"text": "La carretera estaba atascada. Hab??a mucho tráfico el d??a de ayer."
},
{
"id": "4",
"text": ":) :( :D"
}
]
}Formatting data into the JSON format is actually surprisingly easy in R. As an example, we use 5 tweets of President Trump. Note the format of data is strictly required.
## Organize the information to use API
trump.api <- tibble(id=1:nrow(trump), text=trump$text)
trump.json.inp <- toJSON(list(documents=trump.api[1:5, ]))
trump.json.inp
## {"documents":[{"id":1,"text":"The Democrats will never be satisfied, no matter what they get, how much they get, or how many pages they get. It will never end, but that’s the way life goes!"},{"id":2,"text":"Uganda must find the kidnappers of the American Tourist and guide before people will feel safe in going there. Bring them to justice openly and quickly!"},{"id":3,"text":"RT @cspan: Rep. @Jim_Jordan on President Trump's tax returns: \"There's no law that says they have to be public.\"\n\nWatch full #Newsmakers in…"},{"id":4,"text":"RT @Jim_Jordan: Dems want President’s tax returns for purely political purposes!\n\nFrightening, but shouldn’t surprise us—same folks used th…"},{"id":5,"text":"RT @Jim_Jordan: Dem talk:\n-Abolish ICE\n-Borderless hemisphere\n-Walls are immoral\n-Illegals should vote\n-Raise taxes\n\n@POTUS action:\n-Regs r…"}]}A key step here is to send information to Microsoft server and then retrieve the output. The R package httr provides functions to communicate with web servers, which is used here. Particularly, the function POST will be used.
cogapikey <- "41043e511ca44ba1ad1c3154066d7e05"
apiurl <- "https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/sentiment"
trump.json.out <- POST(apiurl,
add_headers(`Ocp-Apim-Subscription-Key` = cogapikey,
`Content-Type` = "application/json"),
body = trump.json.inp
)
trump.json.out %>%
content() %>%
flatten_df()
## # A tibble: 5 x 2
## id score
## <chr> <dbl>
## 1 1 0.818
## 2 2 0.899
## 3 3 0.5
## 4 4 0.116
## 5 5 0.794The URL for getting other information about the text.
- Detect language: https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/languages
- Key phrases: https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/keyPhrases
- Linked entities: https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/entities
- Sentiment: https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/sentiment
For example, we can get the key phrases for the tweets above.
cogapikey <- "41043e511ca44ba1ad1c3154066d7e05"
apiurl <- "https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/keyPhrases"
trump.json.out <- POST(apiurl,
add_headers(`Ocp-Apim-Subscription-Key` = cogapikey,
`Content-Type` = "application/json"),
body = trump.json.inp
)
trump.json.out %>%
content() -> trump.key.phrases
trump.key.phrases$documents[[1]]
## $id
## [1] "1"
##
## $keyPhrases
## $keyPhrases[[1]]
## [1] "way life"
##
## $keyPhrases[[2]]
## [1] "pages"
##
## $keyPhrases[[3]]
## [1] "Democrats"
##
## $keyPhrases[[4]]
## [1] "matter"The output is an irregular list. In order to process the output, we write a function key.phrases().
key.phrases <- function(.data){
## find the number of documents
documents <- .data$documents
out <- NULL
for (i in 1:length(documents)){
if (length(documents[[i]]$keyPhrases)!=0){
out <- bind_rows(out,
tibble(id=as.numeric(documents[[i]]$id),
phrase= unlist(documents[[i]]$keyPhrases)))
}
}
out
}Now to use the function to process the results.
trump.json.out %>%
content() %>%
key.phrases()
## # A tibble: 36 x 2
## id phrase
## <dbl> <chr>
## 1 1 way life
## 2 1 pages
## 3 1 Democrats
## 4 1 matter
## 5 2 guide
## 6 2 kidnappers
## 7 2 people
## 8 2 American Tourist
## 9 2 Uganda
## 10 2 justice
## # ... with 26 more rows4.5.1.2 Trump tweet analysis
We now analyze the latest 100 tweets of President Trump this year.
## prepare data
trump.api <- tibble(id=1:100, text=trump$text[1:100])
trump.json.inp <- toJSON(list(documents=trump.api))
## sentiment analysis
api.sent <- "https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/sentiment"
trump.json.out <- POST(api.sent,
add_headers(`Ocp-Apim-Subscription-Key` = cogapikey, `Content-Type` = "application/json"),
body = trump.json.inp
)
trump.sentiment <- trump.json.out %>%
content() %>%
flatten_df() %>%
bind_cols(tweet=trump$text[1:100])
trump.sentiment
## # A tibble: 100 x 3
## id score tweet
## <chr> <dbl> <chr>
## 1 1 0.818 The Democrats will never be satisfied, no matter what they get,~
## 2 2 0.899 Uganda must find the kidnappers of the American Tourist and gui~
## 3 3 0.5 "RT @cspan: Rep. @Jim_Jordan on President Trump's tax returns: ~
## 4 4 0.116 "RT @Jim_Jordan: Dems want President’s tax returns for purely p~
## 5 5 0.794 "RT @Jim_Jordan: Dem talk:\n-Abolish ICE\n-Borderless hemispher~
## 6 6 0.5 “Jerry Nadler is not entitled to this information. He is doing ~
## 7 7 0.0626 “The reason the whole process seems so politicized is that Demo~
## 8 8 0.243 ....Mexico must apprehend all illegals and not let them make th~
## 9 9 0.752 "More apprehensions (captures)\nat the Southern Border than in ~
## 10 10 0.981 ....I am pleased to announce that Kevin McAleenan, the current ~
## # ... with 90 more rows## Key phrases analysis
api.key <- "https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/keyPhrases"
trump.json.out <- POST(apiurl,
add_headers(`Ocp-Apim-Subscription-Key` = cogapikey, `Content-Type` = "application/json"),
body = trump.json.inp
)
trump.phases <- trump.json.out %>%
content() %>%
key.phrases()
trump.phases
## # A tibble: 641 x 2
## id phrase
## <dbl> <chr>
## 1 1 way life
## 2 1 pages
## 3 1 Democrats
## 4 1 matter
## 5 2 guide
## 6 2 kidnappers
## 7 2 people
## 8 2 American Tourist
## 9 2 Uganda
## 10 2 justice
## # ... with 631 more rows
head(sort(table(trump.phases$phrase), decreasing=TRUE))
##
## Democrats RT amp Collusion Mexico Dems
## 18 16 13 11 9 84.5.2 Google Cloud Natural Language
The Google API for text analysis can be conducted in a similar way.
The URL https://language.googleapis.com/v1/documents:analyzeSentiment is with the following options
- analyzeEntities
- analyzeEntitySentiment
- analyzeSentiment
- analyzeSyntax
- annotateText
- classifyText
Below we get the sentiment of the tweet. The API only allows the analysis of one document at a time.
trump.json.inp <- toJSON(list(document=list(type="PLAIN_TEXT", content=trump$text[2]), encodingType="UTF8"), auto_unbox = TRUE)
trump.json.inp
## {"document":{"type":"PLAIN_TEXT","content":"Uganda must find the kidnappers of the American Tourist and guide before people will feel safe in going there. Bring them to justice openly and quickly!"},"encodingType":"UTF8"}
cogapikey <- "0e703026976d2485cd2045555fa6eb75c3820b76"
apiurl <- "https://language.googleapis.com/v1/documents:analyzeSentiment?key=AIzaSyAQrqxQgBtVdzOdnXEQu-H13ZWA3q6_ATM"
trump.json.out <- POST(apiurl,
add_headers( `Content-Type` = "application/json"),
body = trump.json.inp
)
trump.json.out %>%
content()
## $documentSentiment
## $documentSentiment$magnitude
## [1] 0.9
##
## $documentSentiment$score
## [1] -0.3
##
##
## $language
## [1] "en"
##
## $sentences
## $sentences[[1]]
## $sentences[[1]]$text
## $sentences[[1]]$text$content
## [1] "Uganda must find the kidnappers of the American Tourist and guide before people will feel safe in going there."
##
## $sentences[[1]]$text$beginOffset
## [1] 0
##
##
## $sentences[[1]]$sentiment
## $sentences[[1]]$sentiment$magnitude
## [1] 0.7
##
## $sentences[[1]]$sentiment$score
## [1] -0.7
##
##
##
## $sentences[[2]]
## $sentences[[2]]$text
## $sentences[[2]]$text$content
## [1] "Bring them to justice openly and quickly!"
##
## $sentences[[2]]$text$beginOffset
## [1] 111
##
##
## $sentences[[2]]$sentiment
## $sentences[[2]]$sentiment$magnitude
## [1] 0.1
##
## $sentences[[2]]$sentiment$score
## [1] 0.1We can also get many analyses in one call to the API.
features <- list(extractSyntax = TRUE,
extractEntities = TRUE,
extractDocumentSentiment = TRUE,
extractEntitySentiment = TRUE,
classifyText = TRUE)
trump.json.inp <- toJSON(
list(document = list(type = "PLAIN_TEXT",
content = trump$text[2]),
encodingType="UTF8"),
auto_unbox = TRUE)
cogapikey <- "0e703026976d2485cd2045555fa6eb75c3820b76"
apiurl <- "https://language.googleapis.com/v1/documents:annotateText?key=AIzaSyAQrqxQgBtVdzOdnXEQu-H13ZWA3q6_ATM"
trump.json.out <- POST(apiurl,
add_headers( `Content-Type` = "application/json"),
body = trump.json.inp
)
trump.json.out %>%
content() Again, processing the output is critically important.
proc.google <- function(.data){
data <- .data
## tibble to save the data
sentiment <- NULL
## get the document sentiment
if (!is.null(data$documentSentiment)){
sentiment <- bind_rows(sentiment,
tibble(score=data$documentSentiment$score,
magnitude=data$documentSentiment$magnitude,
salience=NA,
type="text", text=NA))
}
## get the sentence sentiment
if (!is.null(data$sentences)){
for (i in 1:length(data$sentences)){
sentiment <- bind_rows(sentiment,
tibble(score=data$sentences[[i]]$sentiment$score,
magnitude=data$sentences[[i]]$sentiment$magnitude,
salience=NA,
type="sentence",
text=data$sentences[[i]]$text$content))
} # close if
} # close for
## get the entries sentiment
if (!is.null(data$entities)){
for (i in 1:length(data$entities)){
sentiment <- bind_rows(sentiment,
tibble(score=data$entities[[i]]$sentiment$score,
magnitude=data$entities[[i]]$sentiment$magnitude,
salience=data$entities[[i]]$salience,
type=data$entities[[i]]$type,
text=data$entities[[i]]$name))
} # close if
} # close for
list(sentiment=sentiment, language=data$language,
category=data$categories)
}trump.json.out %>%
content() %>%
proc.google()
## $sentiment
## NULL
##
## $language
## NULL
##
## $category
## NULL4.6 Date and time
Date and time can usually be viewed as special strings. For example, the date() function directly returns a string Mon Apr 08 16:36:39 2019.
4.6.1 Base R functions
There are also date types in R which makes the use of date an time more flexible.
- To get the current date and time of your system
Sys.time()
## [1] "2019-04-08 16:36:39 EDT"
Sys.Date()
## [1] "2019-04-08"- Format dates
time <- Sys.time()
time
## [1] "2019-04-08 16:36:39 EDT"
format(time, "%Y-%m-%d %H:%M:%S %Z")
## [1] "2019-04-08 16:36:39 EDT"
format(time, "%Y-%m-%d %H:%M:%S")
## [1] "2019-04-08 16:36:39"
format(time, "%Y/%m/%d %H:%M:%S")
## [1] "2019/04/08 16:36:39"
format(time, "%a, %d %b %Y")
## [1] "Mon, 08 Apr 2019"
format(time, "%A, %d %B %Y")
## [1] "Monday, 08 April 2019"
format(time, "%a")
## [1] "Mon"
format(time, "%u")
## [1] "1"
format(time, "%U")
## [1] "14"- Date as a value. We can convert a date to a value of seconds since the epoch/origin of time. By default, the original time is
1970-01-01 00:00.00 UTC.
as.numeric(as.Date('1970-01-01 00:00.00 UTC'))
## [1] 0
as.numeric(Sys.time())
## [1] 1554755799- Add time
time + 60
## [1] "2019-04-08 16:37:39 EDT"
time + 60*60
## [1] "2019-04-08 17:36:39 EDT"
time + 60*60*24
## [1] "2019-04-09 16:36:39 EDT"- Create a date value (add the differences between “POSIXlt” and “POSIXct”)
strptime('2019-01-17', '%Y-%m-%d')
## [1] "2019-01-17 EST"
strptime('2019-01-17 19:22:03', '%Y-%m-%d %H:%M:%S')
## [1] "2019-01-17 19:22:03 EST"4.6.2 Operations on time
We now use the religious data as an example to show how to deal with dates and times.
daily <- read.csv('data/relig-daily.csv', stringsAsFactors = FALSE)
daily.sel <- daily %>%
select(id, start, end, age, mixm:nmcm)
head(daily.sel)
## id start end age mixm micm spirxm
## 1 27 2009-10-20 22:21:23 2009-10-20 22:29:39 18 7.500000 5.060000 7.693333
## 2 27 2009-10-22 21:04:43 2009-10-22 21:12:02 18 5.846667 4.000000 7.090000
## 3 27 2009-10-18 22:11:46 2009-10-18 22:26:12 18 7.220000 5.130000 7.950000
## 4 27 2009-11-13 21:39:46 2009-11-13 21:45:39 18 7.930000 5.376667 7.500000
## 5 27 2009-10-12 20:54:11 2009-10-12 21:07:10 18 8.226667 5.576667 7.783333
## 6 27 2009-10-26 00:06:57 2009-10-26 00:15:52 18 7.580000 5.320000 7.886667
## spircm nmxm nmcm
## 1 5.416667 7.023333 5.493333
## 2 4.376667 5.776667 4.176667
## 3 5.546667 6.250000 4.566667
## 4 5.850000 6.483333 4.910000
## 5 5.076667 7.156667 3.556667
## 6 5.873333 6.916667 4.916667- Convert
startandendto time format
daily.sel$start <-strptime(daily.sel$start, "%Y-%m-%d %H:%M:%S")
daily.sel$end <-strptime(daily.sel$end, "%Y-%m-%d %H:%M:%S")
head(daily.sel)
## id start end age mixm micm spirxm
## 1 27 2009-10-20 22:21:23 2009-10-20 22:29:39 18 7.500000 5.060000 7.693333
## 2 27 2009-10-22 21:04:43 2009-10-22 21:12:02 18 5.846667 4.000000 7.090000
## 3 27 2009-10-18 22:11:46 2009-10-18 22:26:12 18 7.220000 5.130000 7.950000
## 4 27 2009-11-13 21:39:46 2009-11-13 21:45:39 18 7.930000 5.376667 7.500000
## 5 27 2009-10-12 20:54:11 2009-10-12 21:07:10 18 8.226667 5.576667 7.783333
## 6 27 2009-10-26 00:06:57 2009-10-26 00:15:52 18 7.580000 5.320000 7.886667
## spircm nmxm nmcm
## 1 5.416667 7.023333 5.493333
## 2 4.376667 5.776667 4.176667
## 3 5.546667 6.250000 4.566667
## 4 5.850000 6.483333 4.910000
## 5 5.076667 7.156667 3.556667
## 6 5.873333 6.916667 4.916667- Calculate the time used to complete the survey
duration <- difftime(daily.sel$end, daily.sel$start)
head(duration)
## Time differences in secs
## [1] 496 439 866 353 779 535
boxplot(as.double(duration)/60)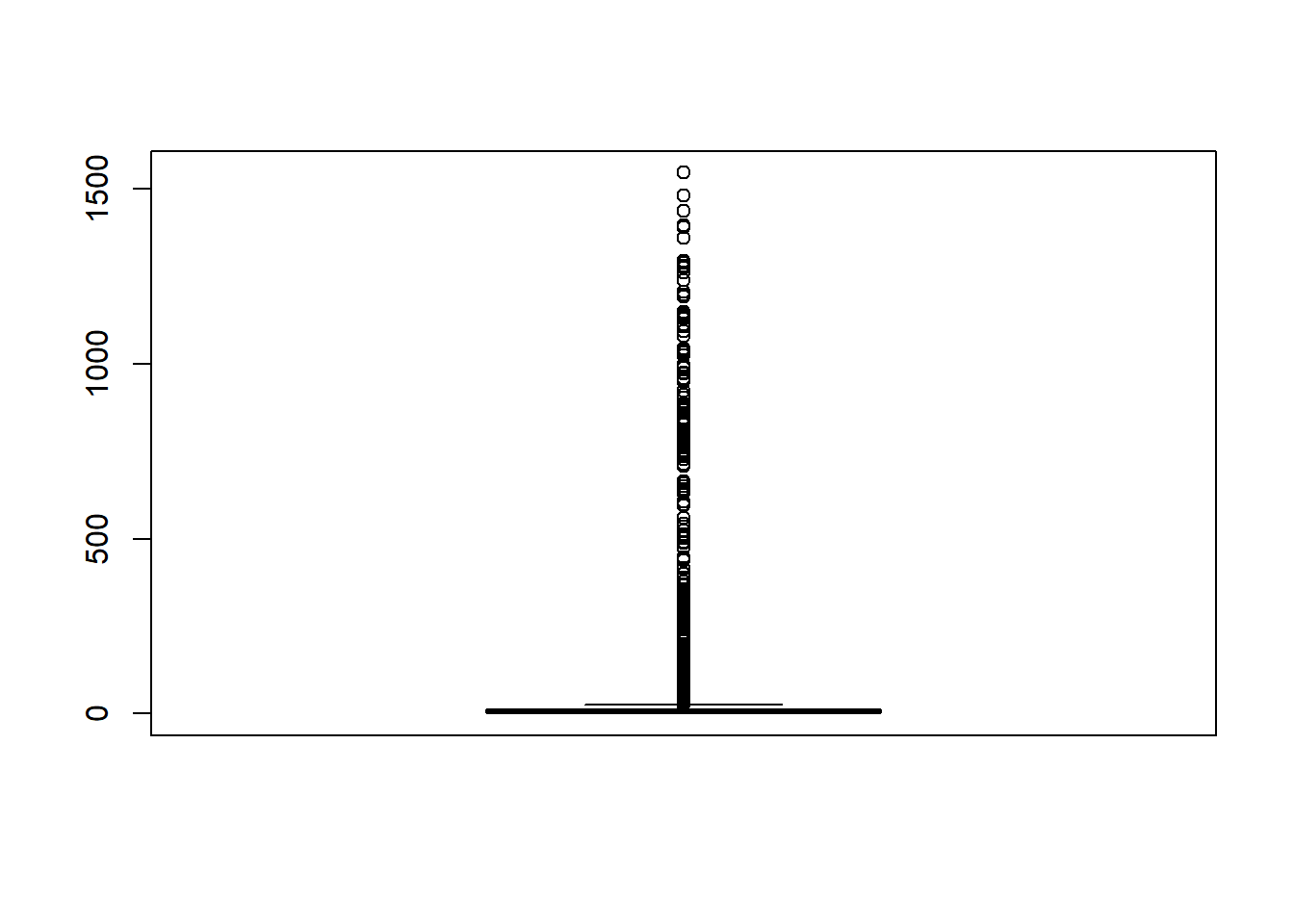
summary(as.double(duration)/60)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.350 4.429 7.117 30.878 12.467 1545.267
which.max(duration)
## [1] 535- Order according to time
sub1 <- daily.sel[daily.sel$id==27, ]
sub1[order(sub1$start), 1:5]
## id start end age mixm
## 37 27 2009-10-03 22:44:42 2009-10-03 22:57:31 18 NA
## 18 27 2009-10-04 22:49:18 2009-10-04 22:57:02 18 NA
## 21 27 2009-10-05 21:20:17 2009-10-05 21:28:10 18 NA
## 12 27 2009-10-06 19:40:23 2009-10-06 19:48:25 18 NA
## 23 27 2009-10-07 19:14:49 2009-10-07 19:20:23 18 NA
## 35 27 2009-10-08 22:01:43 2009-10-08 22:15:45 18 9.040000
## 34 27 2009-10-09 19:05:49 2009-10-09 19:14:41 18 7.463333
## 19 27 2009-10-10 21:27:24 2009-10-10 21:43:54 18 7.616667
## 31 27 2009-10-11 22:15:43 2009-10-11 22:58:48 18 6.873333
## 5 27 2009-10-12 20:54:11 2009-10-12 21:07:10 18 8.226667
## 29 27 2009-10-13 20:22:11 2009-10-13 20:32:19 18 4.993333
## 10 27 2009-10-14 22:44:00 2009-10-14 22:52:21 18 7.390000
## 25 27 2009-10-15 20:52:56 2009-10-15 21:01:54 18 6.536667
## 39 27 2009-10-17 10:17:25 2009-10-17 10:25:36 18 8.000000
## 27 27 2009-10-17 21:08:38 2009-10-17 21:17:30 18 8.390000
## 3 27 2009-10-18 22:11:46 2009-10-18 22:26:12 18 7.220000
## 38 27 2009-10-19 21:39:24 2009-10-19 21:54:37 18 7.426667
## 1 27 2009-10-20 22:21:23 2009-10-20 22:29:39 18 7.500000
## 9 27 2009-10-21 19:55:42 2009-10-21 20:07:04 18 6.543333
## 2 27 2009-10-22 21:04:43 2009-10-22 21:12:02 18 5.846667
## 7 27 2009-10-23 18:31:01 2009-10-23 18:38:11 18 7.343333
## 26 27 2009-10-24 19:11:35 2009-10-24 19:18:42 18 7.540000
## 6 27 2009-10-26 00:06:57 2009-10-26 00:15:52 18 7.580000
## 32 27 2009-10-26 21:06:39 2009-10-26 21:13:08 18 7.726667
## 16 27 2009-10-27 21:08:25 2009-10-27 21:16:33 18 6.423333
## 40 27 2009-10-28 19:38:08 2009-10-28 19:53:35 18 7.290000
## 11 27 2009-10-29 20:36:34 2009-10-29 20:48:26 18 6.050000
## 30 27 2009-10-31 12:29:39 2009-10-31 12:36:00 18 6.993333
## 17 27 2009-11-01 14:20:21 2009-11-01 15:28:45 18 7.540000
## 33 27 2009-11-01 22:37:35 2009-11-01 23:00:38 18 7.166667
## 15 27 2009-11-03 16:26:15 2009-11-03 16:36:13 18 7.390000
## 24 27 2009-11-03 21:03:51 2009-11-03 21:13:34 18 7.116667
## 28 27 2009-11-04 21:29:21 2009-11-04 21:35:34 18 7.263333
## 4 27 2009-11-13 21:39:46 2009-11-13 21:45:39 18 7.930000
## 8 27 2009-11-14 22:20:33 2009-11-14 22:27:17 18 8.090000
## 22 27 2009-11-15 22:27:59 2009-11-15 22:43:32 18 7.796667
## 14 27 2009-11-16 21:16:18 2009-11-16 21:38:50 18 8.276667
## 20 27 2009-11-17 18:14:00 2009-11-17 18:23:33 18 7.490000
## 36 27 2009-11-18 20:03:07 2009-11-18 20:13:03 18 6.976667
## 13 27 2009-11-19 18:36:54 2009-11-19 18:41:31 18 7.096667- Interval between surveys
sub2 <- sub1[order(sub1$start), ]
diff(sub2$start)
## Time differences in hours
## [1] 24.076667 22.516389 22.335000 23.573889 26.781667 21.068333
## [7] 26.359722 24.805278 22.641111 23.466667 26.363611 22.148889
## [13] 37.408056 10.853611 25.052222 23.460556 24.699722 21.571944
## [19] 25.150278 21.438333 24.676111 28.922778 20.995000 24.029444
## [25] 22.495278 24.973889 39.884722 26.845000 8.287222 41.811111
## [31] 4.626667 24.425000 216.173611 24.679722 24.123889 22.805278
## [37] 20.961667 25.818611 22.563056- Round time
round(daily.sel[daily.sel$id==27,'start'], 'hours')
## [1] "2009-10-20 22:00:00 EDT" "2009-10-22 21:00:00 EDT"
## [3] "2009-10-18 22:00:00 EDT" "2009-11-13 22:00:00 EST"
## [5] "2009-10-12 21:00:00 EDT" "2009-10-26 00:00:00 EDT"
## [7] "2009-10-23 19:00:00 EDT" "2009-11-14 22:00:00 EST"
## [9] "2009-10-21 20:00:00 EDT" "2009-10-14 23:00:00 EDT"
## [11] "2009-10-29 21:00:00 EDT" "2009-10-06 20:00:00 EDT"
## [13] "2009-11-19 19:00:00 EST" "2009-11-16 21:00:00 EST"
## [15] "2009-11-03 16:00:00 EST" "2009-10-27 21:00:00 EDT"
## [17] "2009-11-01 14:00:00 EST" "2009-10-04 23:00:00 EDT"
## [19] "2009-10-10 21:00:00 EDT" "2009-11-17 18:00:00 EST"
## [21] "2009-10-05 21:00:00 EDT" "2009-11-15 22:00:00 EST"
## [23] "2009-10-07 19:00:00 EDT" "2009-11-03 21:00:00 EST"
## [25] "2009-10-15 21:00:00 EDT" "2009-10-24 19:00:00 EDT"
## [27] "2009-10-17 21:00:00 EDT" "2009-11-04 21:00:00 EST"
## [29] "2009-10-13 20:00:00 EDT" "2009-10-31 12:00:00 EDT"
## [31] "2009-10-11 22:00:00 EDT" "2009-10-26 21:00:00 EDT"
## [33] "2009-11-01 23:00:00 EST" "2009-10-09 19:00:00 EDT"
## [35] "2009-10-08 22:00:00 EDT" "2009-11-18 20:00:00 EST"
## [37] "2009-10-03 23:00:00 EDT" "2009-10-19 22:00:00 EDT"
## [39] "2009-10-17 10:00:00 EDT" "2009-10-28 20:00:00 EDT"
trunc(daily.sel[daily.sel$id==27,'start'], 'hours')
## [1] "2009-10-20 22:00:00 EDT" "2009-10-22 21:00:00 EDT"
## [3] "2009-10-18 22:00:00 EDT" "2009-11-13 21:00:00 EST"
## [5] "2009-10-12 20:00:00 EDT" "2009-10-26 00:00:00 EDT"
## [7] "2009-10-23 18:00:00 EDT" "2009-11-14 22:00:00 EST"
## [9] "2009-10-21 19:00:00 EDT" "2009-10-14 22:00:00 EDT"
## [11] "2009-10-29 20:00:00 EDT" "2009-10-06 19:00:00 EDT"
## [13] "2009-11-19 18:00:00 EST" "2009-11-16 21:00:00 EST"
## [15] "2009-11-03 16:00:00 EST" "2009-10-27 21:00:00 EDT"
## [17] "2009-11-01 14:00:00 EST" "2009-10-04 22:00:00 EDT"
## [19] "2009-10-10 21:00:00 EDT" "2009-11-17 18:00:00 EST"
## [21] "2009-10-05 21:00:00 EDT" "2009-11-15 22:00:00 EST"
## [23] "2009-10-07 19:00:00 EDT" "2009-11-03 21:00:00 EST"
## [25] "2009-10-15 20:00:00 EDT" "2009-10-24 19:00:00 EDT"
## [27] "2009-10-17 21:00:00 EDT" "2009-11-04 21:00:00 EST"
## [29] "2009-10-13 20:00:00 EDT" "2009-10-31 12:00:00 EDT"
## [31] "2009-10-11 22:00:00 EDT" "2009-10-26 21:00:00 EDT"
## [33] "2009-11-01 22:00:00 EST" "2009-10-09 19:00:00 EDT"
## [35] "2009-10-08 22:00:00 EDT" "2009-11-18 20:00:00 EST"
## [37] "2009-10-03 22:00:00 EDT" "2009-10-19 21:00:00 EDT"
## [39] "2009-10-17 10:00:00 EDT" "2009-10-28 19:00:00 EDT"- Sort time
daily %>%
select(id, survey, start, nmcm) %>%
filter(id==27) %>%
arrange(start)
## id survey start nmcm
## 1 27 3 2009-10-03 22:44:42 NA
## 2 27 4 2009-10-04 22:49:18 NA
## 3 27 5 2009-10-05 21:20:17 NA
## 4 27 6 2009-10-06 19:40:23 NA
## 5 27 7 2009-10-07 19:14:49 NA
## 6 27 8 2009-10-08 22:01:43 4.530000
## 7 27 9 2009-10-09 19:05:49 4.810000
## 8 27 10 2009-10-10 21:27:24 3.843333
## 9 27 11 2009-10-11 22:15:43 4.330000
## 10 27 12 2009-10-12 20:54:11 3.556667
## 11 27 13 2009-10-13 20:22:11 3.753333
## 12 27 14 2009-10-14 22:44:00 4.336667
## 13 27 15 2009-10-15 20:52:56 4.573333
## 14 27 16 2009-10-17 10:17:25 5.343333
## 15 27 17 2009-10-17 21:08:38 5.170000
## 16 27 18 2009-10-18 22:11:46 4.566667
## 17 27 19 2009-10-19 21:39:24 5.116667
## 18 27 20 2009-10-20 22:21:23 5.493333
## 19 27 21 2009-10-21 19:55:42 4.760000
## 20 27 22 2009-10-22 21:04:43 4.176667
## 21 27 23 2009-10-23 18:31:01 4.916667
## 22 27 24 2009-10-24 19:11:35 4.763333
## 23 27 25 2009-10-26 00:06:57 4.916667
## 24 27 26 2009-10-26 21:06:39 5.116667
## 25 27 27 2009-10-27 21:08:25 4.253333
## 26 27 28 2009-10-28 19:38:08 5.290000
## 27 27 29 2009-10-29 20:36:34 4.760000
## 28 27 30 2009-10-31 12:29:39 4.410000
## 29 27 31 2009-11-01 14:20:21 4.350000
## 30 27 32 2009-11-01 22:37:35 5.100000
## 31 27 33 2009-11-03 16:26:15 4.886667
## 32 27 34 2009-11-03 21:03:51 5.066667
## 33 27 35 2009-11-04 21:29:21 4.800000
## 34 27 44 2009-11-13 21:39:46 4.910000
## 35 27 45 2009-11-14 22:20:33 4.793333
## 36 27 46 2009-11-15 22:27:59 5.326667
## 37 27 47 2009-11-16 21:16:18 5.290000
## 38 27 48 2009-11-17 18:14:00 4.686667
## 39 27 49 2009-11-18 20:03:07 5.010000
## 40 27 50 2009-11-19 18:36:54 4.5366674.7 References
- http://trumptwitterarchive.com/howto/all_tweets.html
- https://books.psychstat.org/textmining/
- https://www.tidytextmining.com/
- https://r4ds.had.co.nz/strings.html
- https://regex101.com/
- https://cloud.google.com/natural-language/
- https://azure.microsoft.com/en-us/services/cognitive-services/text-analytics/